Vivado中使用ZYNQ驱动4.3寸RGB屏步骤 |
您所在的位置:网站首页 › 27寸4K屏用238寸驱动板 › Vivado中使用ZYNQ驱动4.3寸RGB屏步骤 |
Vivado中使用ZYNQ驱动4.3寸RGB屏步骤
|
1、引言
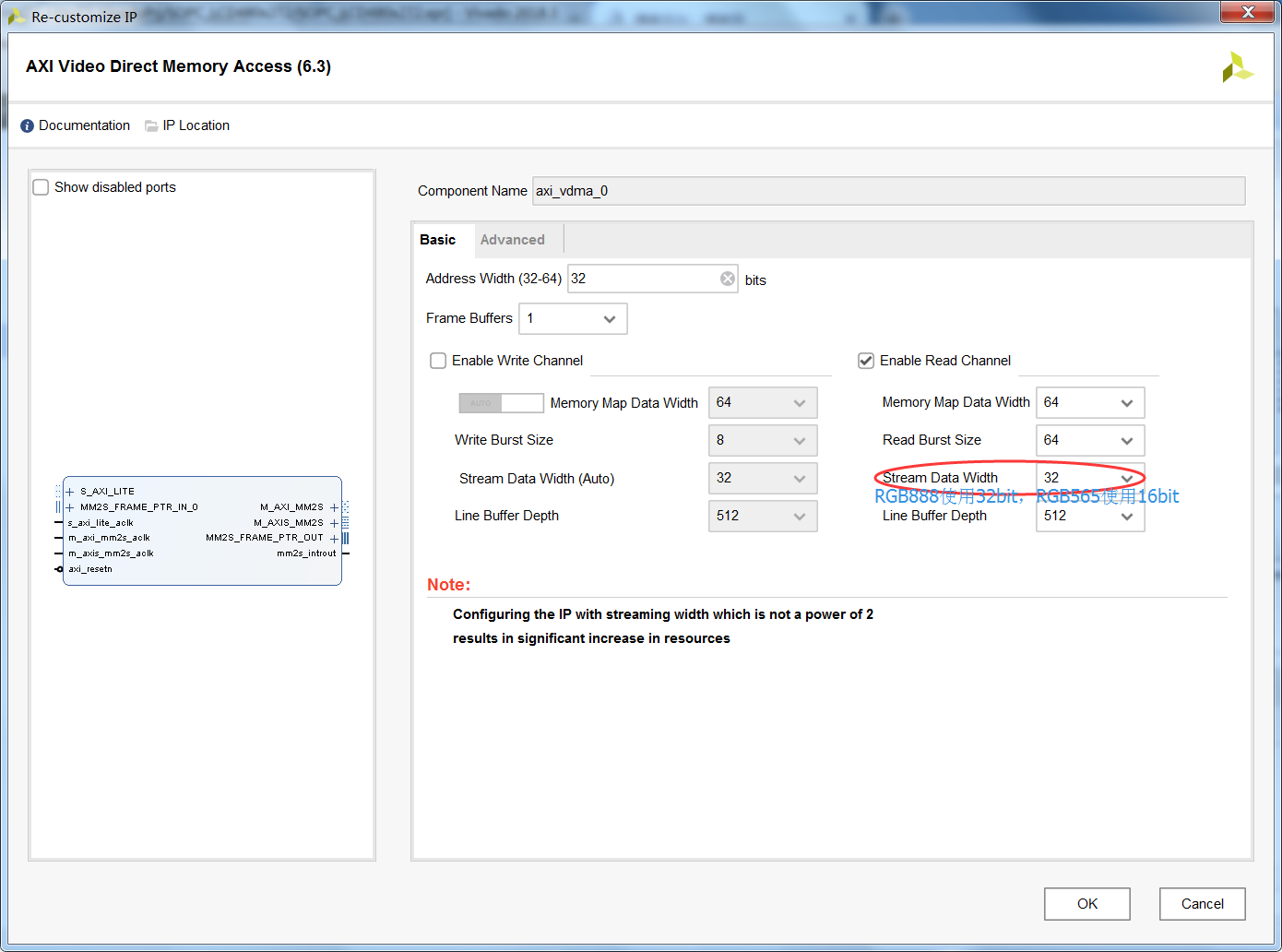
最近由于实验需求,要将图片通过屏幕显示出来,正常来讲使用的ZYNQ平台能够支持DisplayPort(UltraScale系列支持)、HDMI或者VGA,但是通常这类显示方式容易占用大量的带宽,而我其实真正需要的只是一种图片的显示结果,并且是那种对于软件应用层面比较容易编写程序的。理论上来说可以选择RGB屏和带有控制器的MCU屏,由于MCU屏需要初始化以及部分驱动代码,在软件编写层面不是那么的简单,因此选择使用RGB屏,屏幕的分辨率为480x272。其实现有的程序可以直接参考正点原子的ZYNQ系列教程,但是提供的工程为了适配不同屏幕尺寸,添加了一些额外的代码,不够精简。笔者从应用出发,假定已经知道了屏幕的参数,包括分辨率和时序等,那么如果建立一个最小的工程,用于简单的屏幕显示。因此有了本文的具体步骤,其中有些地方笔者也不是很清楚,在此列举出的步骤起一个抛砖引玉的作用。 实验测试平台参数: ZYNQ型号:xc7z010;(理论上任意型号均可) 屏幕型号:正点原子4.3寸480x272兼容屏幕;(本文只实现了显示功能,触摸未做) 软件版本:Vivado 2018.3 工程源码:点我下载(为了减少文件大小,删除了部分生成的文件,使用过程中记得重新点击Generate Output Products,然后再生成比特流) 2、Vivado硬件实验步骤 2.1 添加ZYNQ核并配置(非ZYNQ系列该步骤可跳过) 根据实际需求,添加ZYNQ核并配置。此处需要注意的是,至少需要一个PS控制PL的GP0端口,以及一个PL读取PS端的HP0口,其中HP0可选择使用32bit或64bit均可,其他系列例如UltraScale设置为128bit亦可。 然后设置PS提供给PL的时钟FCLK_CLK0的频率为100MHz;(此处设置为其他频率也可以,但是需要考虑RGB屏幕所需要的带宽,屏幕分辨率越高,对时钟频率的要求越高) 此处需要说明的是笔者使用的4.3寸屏幕驱动时钟为9MHz,因此添加Clocking Wizard(IP核),使用PLL将100MHz输入频率调整为9MHz输出频率。 2.2 添加VDMA核,并配置相关参数此处需要注意的是如果只用到了显示功能,而没有摄像头等功能的话,设置为只读即可,配置截图如下:
将VDMA的数据流转换为带有时序控制的视频流,配置如下:
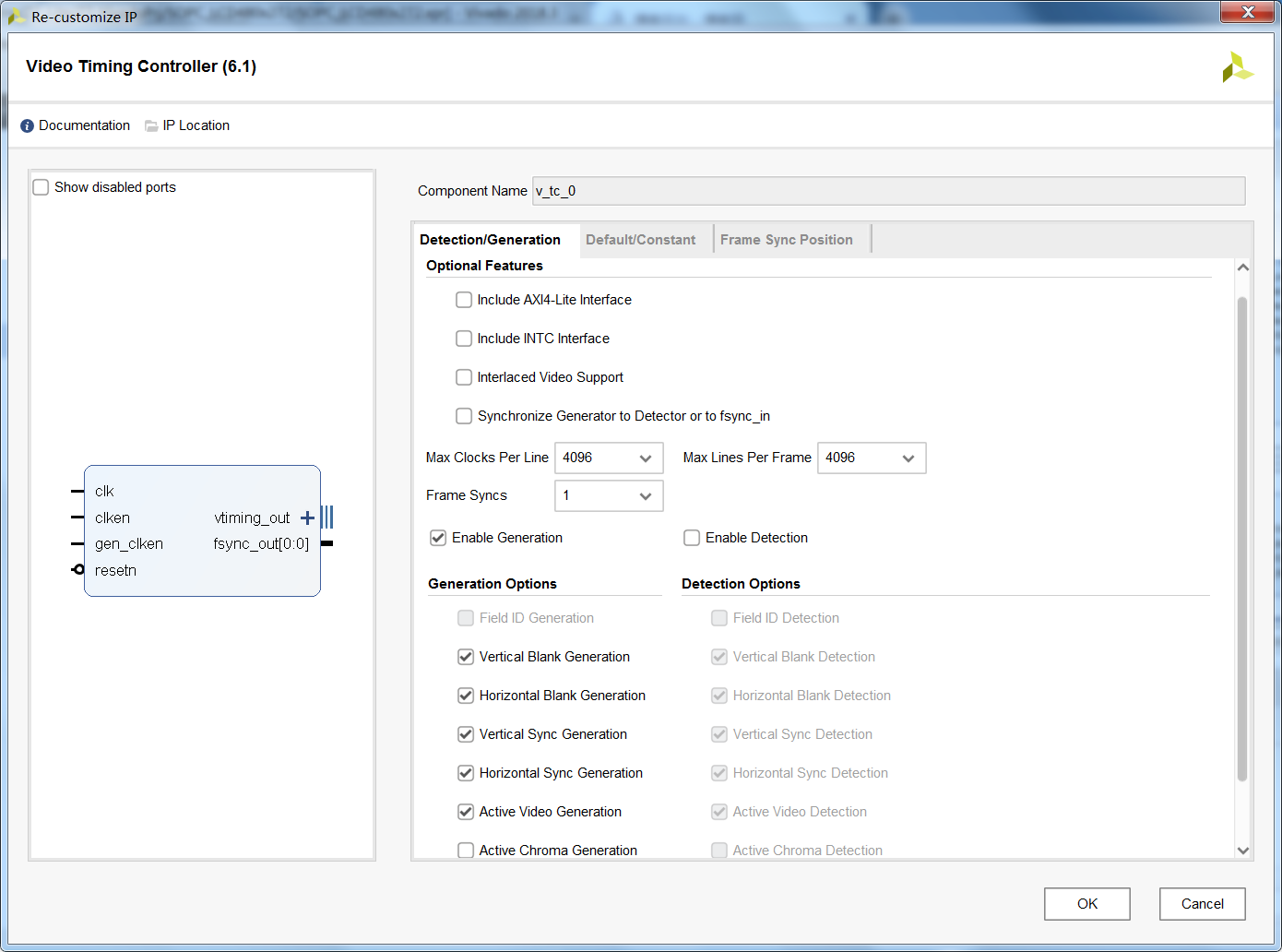
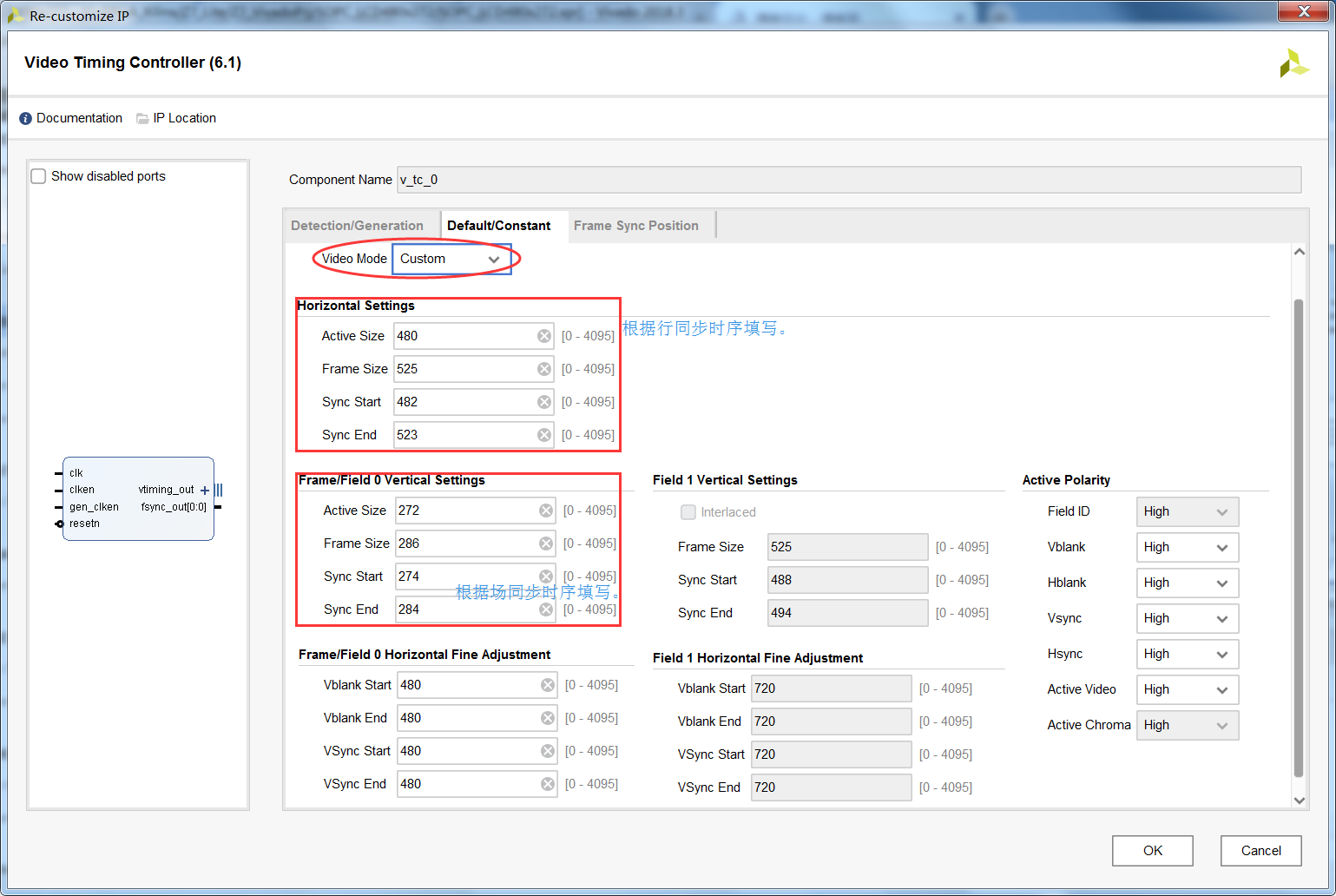
基本上配置保持默认不变,此处需要说明的是,笔者曾尝试将此IP核设置为支持RGB565形式,但是尝试过后没有成功,因此采用了折中的方法,将VDMA中的数据位宽设置为16bit,然后将16bit经过rgb565转换为rgb888后,扩展为24bit,然后再与Stream to Video Out相连接。 2.4 添加Video Timing Controller,并配置显示的时序参数此处需要配置核心为显示参数,如果是后续需要直接用标准的视频显示尺寸,Xilinx官方提供了标准的时序参数,可以直接采用,无需配置。此处的配置如下:
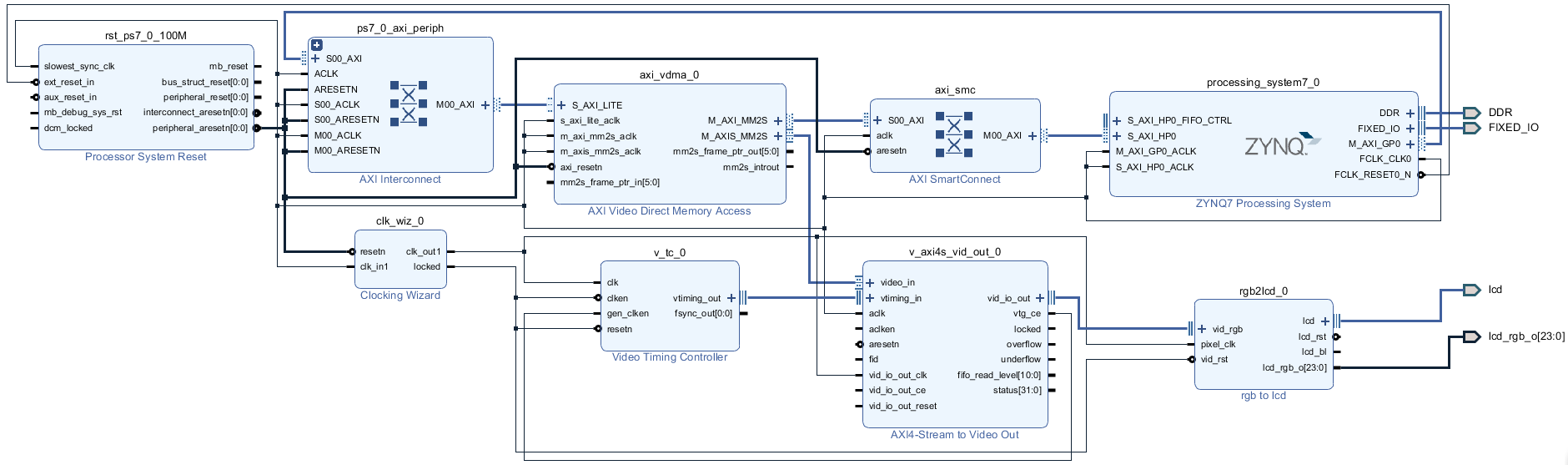
参考正点原子给出的教程,添加该IP核。笔者看了其中的源码功能,发现是对Stream to Video Out中信号的整理,并无逻辑在里面。 2.5 其他配置最后连接过程可以直接参考工程文件,各模块连接如下:
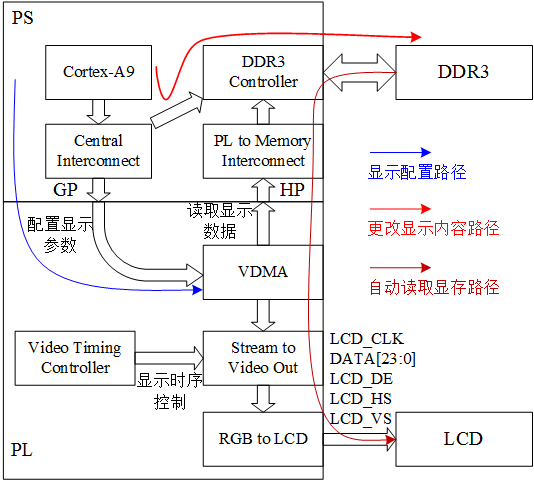
首先用一个显示的路径图来说明:
其中主要配置的是VDMA,包括显示内容的地址,然后VDMA自动读取存储器中的显示数据,并转换为Stream数据流,在显示时序的控制下,输出至外界的LCD屏幕。 在这个过程中,如果主控制器(Cortex-A9)想要更改显示的内容,只需要更改DDR3中的数据,即可直接对应到屏幕上的任意一个像素。 2.7 带宽分析对于带宽的分析,主要用于得出显示过程中占用的外部存储器带宽,从而为后续带宽的分配进行量化分析。例如,在嵌入式卷积神经网络加速等应用中,算法的加速需要将考虑将计算的中间结果导出至外部DDR中,由此带来的带宽消耗与片上BRAM存储分配,需要进行详细的量化分析,从而得到更好的理论计算结果。 此处对于带宽的分析分为粗粒度分析和细粒度分析。 (1)粗粒度分析 其中粗粒度分析比较简单,假定显示过程中每个时钟均存在数据传输,直接根据显示的时钟频率乘以显示的数据位宽即可,例如在RGB888中,通常采用32bit位宽存储一个像素点数据,那么此时带宽占用的粗粒度分析如下:
在公式(1)中,单个像素(Pixel)占用4个字节,高8位的一个字节填充为0,那么RGB888占用36MB/s的带宽;如果采用RGB565的方式,那么单个像素占用2个字节,最终带宽为RGB888的一半,即18MB/s;如果采用256位色的方式,单个像素占用1个字节,最终带宽再减半,即9MB/s。 (2)细粒度分析 细粒度的分析需要考虑显示的时序,根据每秒钟得到的帧数(FPS),然后使用LCD的分辨率(480x272)得到真实的带宽消耗。具体如下:
其中W为显示屏的行像素480,H为显示屏的列像素272,Tw为显示屏的行时序显示周期,Th为显示屏的帧(列)时序显示周期,f为显示的时钟频率,Pixel为单个像素的字节数。 那么经过公式(2)分析可得细粒度条件下的带宽约为29.85MB/s,具体分析如下:
同理,若采用RGB565,则带宽减半,降低为约14.93MB/s;若采用256位色,再次降低,约为7.46MB/s。 3、SDK软件操作步骤软件代码的编写比较简单,具体代码如下,其中对于VDMA参考了正点原子ZYNQ教程中给出的相关源码,与之相比减少了动态时钟的配置,缺点是不能够自动适应屏幕的尺寸,是一种简化的设计方法。 #include #include "xil_cache.h" #include "sleep.h" #include "xparameters.h" #include "xaxivdma.h" #include "vdma_api/vdma_api.h" XAxiVdma vdma; volatile unsigned int LCD_Buf[272][480]; const unsigned int LCD_Buf_Addr = (unsigned int)(&(LCD_Buf[0][0])); unsigned int color_index[3]={0xff0000, 0x00ff00, 0x0000ff}; int main(void) { int i=0; run_vdma_frame_buffer(&vdma, XPAR_AXI_VDMA_0_DEVICE_ID, 480, 272, LCD_Buf_Addr, 0, 0, ONLY_READ); for(i=0; i |

【本文地址】
今日新闻 |
推荐新闻 |