[SIGMOD 2012]Query optimization in Microsoft SQL Server PDW |
您所在的位置:网站首页 › 240墙cad多线样式怎么设置 › [SIGMOD 2012]Query optimization in Microsoft SQL Server PDW |
[SIGMOD 2012]Query optimization in Microsoft SQL Server PDW
|
总结 PDW QO是paper描述了SQL Server MPP查询优化器的设计与实现,Paralled Data Warehouse产品的查询优化器(PDW QO)。PDW QO是基于SQL Server单机Cascade优化器技术实现的针对分布式查询的CBO优化器。PDW QO在控制节点采用两阶段方式制定DPlan(分布式执行计划): 基于单机Cascade优化器架构,使用全局统计信息,产生若干个潜在winner的memo结构根据数据的分布信息,对这些候选plans进行枚举和剪枝,选择最佳,生成分布式的执行计划。并将这个分布式执行计划树转换为DSQL语句(扩展SQL),分发到各计算节点执行。在控制节点制定分布式执行计划时,会根据数据重分布的操作将整棵查询执行树切割成不同的子树。每个子树对应查询计划的一个阶段,就是GreenPlum中的slice。每个slice都被转换成DSQL语句,在各个计算节点的sql server上执行,互相之间通过网络,发送到远端时要全物化,同时会收集物化的中间结果的统计信息,然后计算节点执行当前slice对应的dsql语句时,会基于这些统计信息重新进行查询优化,可能会有本地更优的计划。 与基于成本的transform相关的一个基本问题是,这些transform是否会导致需要评估的替代方案的组合数量爆炸,以及它们是否会在查询优化的成本和SQL执行的成本之间提供权衡。PDW优化器在这方面有一个非常重要的搜索优化,即timeout机制+从候选plans选取“seed”plans。 SQL Server优化器的timeout机制,不会生成所有可能的plans。在MEMO中基于全局统计信息的可能winner的plans对所考虑的Search space有很大的影响。为了提升PDW查询优化的效率,尽量不穷举所有的备选plans,而是从备选plans中考虑table的数据分布信息以高效配置DMS算子,选择部分"优质plans",即“seed”plans。这个考虑数据分布的方式和interesting order类似,从上到下提出require distribution,从下向上提出provide distribution,进行匹配,不满足增加exchange,这个选种子plans时,尽量选择不需要增加exchange的候选plans。 SQL Server PDW架构SQL Server PDW是一个share nothing的MPP架构,部署方式为一个control node(控制节点)和多个compute node(计算节点),架构图如下: 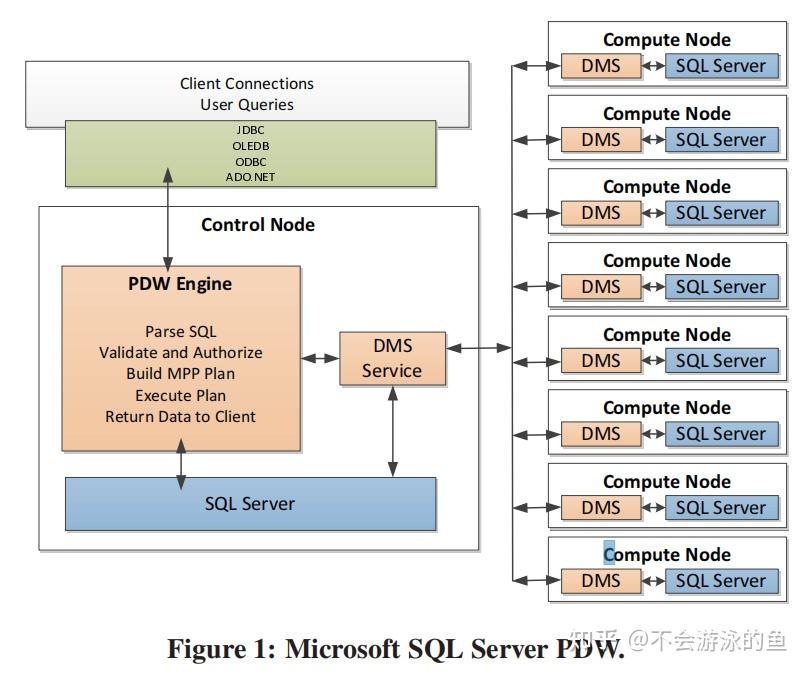 control node一个SQL Server RDBMS实例提供对客户端应用的连接接口负责query的语法解析创建分布式执行计划向compute节点下发执行计划的stepstrace执行计划的steps汇集最终结果,并返回给用户通过本节点的DMS向计算结算发送执行计划,并汇集最终结果compute node一个SQL Server RDBMS实例用户数据存储,执行query通过本节点的DMS实现节点间数据的转移,包括汇集和重分布用户数据表,以hash分片或复制表的方式存储到compute node上,即每个节点存储用户数据的一部分全局元数据表,控制节点存储和更新全局元数据 control node一个SQL Server RDBMS实例提供对客户端应用的连接接口负责query的语法解析创建分布式执行计划向compute节点下发执行计划的stepstrace执行计划的steps汇集最终结果,并返回给用户通过本节点的DMS向计算结算发送执行计划,并汇集最终结果compute node一个SQL Server RDBMS实例用户数据存储,执行query通过本节点的DMS实现节点间数据的转移,包括汇集和重分布用户数据表,以hash分片或复制表的方式存储到compute node上,即每个节点存储用户数据的一部分全局元数据表,控制节点存储和更新全局元数据control node将用户的query转换为一个分布式执行计划(DSQL plan),DSQL可以理解为一个分布式的operator tree,包含一系列的算子(DSQL Operations)。DSQL plan主要有两部分组成: SQL operations,也就是计算类算子,例如sort、select,负责计算DMS operations,数据转移算子,负责在不同节点间转移数据,例如shuttle算子、broadcast算子、gather算子PDW查询优化总体流程PDW优化器位于控制节点内,PDW查询优化的流程如下: 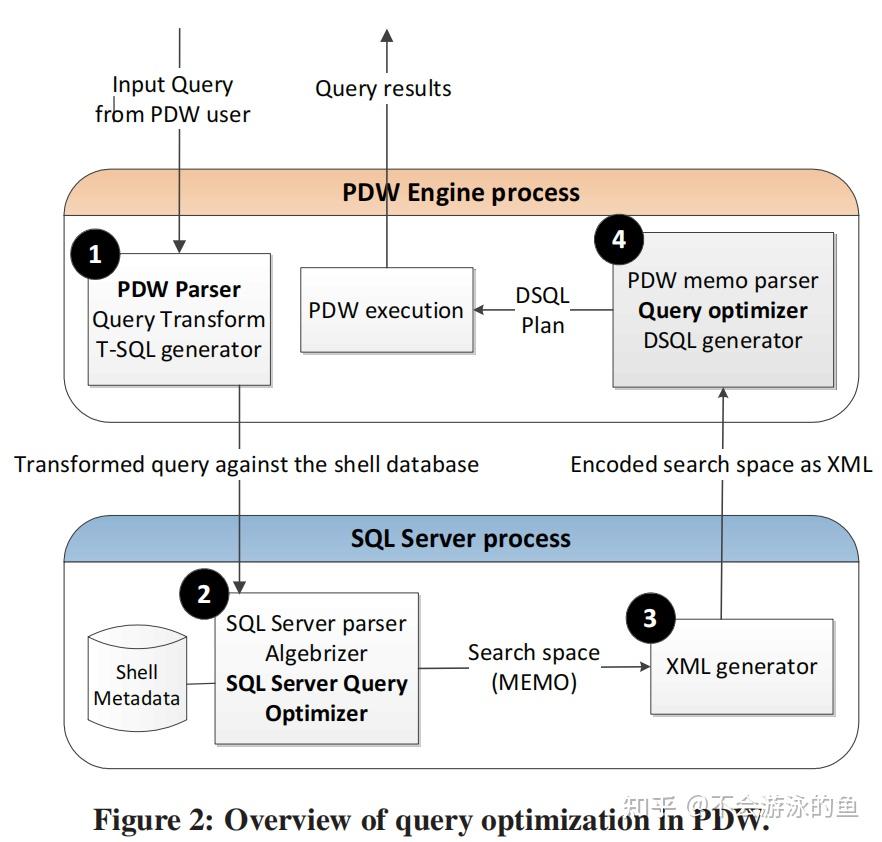 1.基于shell database中存储的全局metadata + 统计信息等,完成单机执行计划的优化 1.a PWD Parser,负责将query string转换为AST 1.b SQL Server Compilation,input为基于AST转换的operator tree 1.b.1 化简input operator tree,其实就是对于经过AST转换的operator tree,基于RBO规则进行转换,生成一个更优的operator tree,作为init plan存储到MEMO中,用于后续的等价变换,如果不理解MEMO的话,可以读下cascade的论文。 1.b.2 对于init plan,基于关系代数规则,进行等价变换,生成多个等价plans,join reorder也是在这个阶段进行 1.b.3 基于用shell database中存储的全局metadata + 统计信息等,完成单机执行计划的优化,生成可能的winner memo,会根据表的大小和列的统计值,评估等价plans的代价 1.b.4 apply physical implementation,为算子枚举物理执行方式,计算相应代价并做一些基本的剪枝 2.基于步骤1中的单机可能winner的plans,结合数据的分布信息,制定最佳分布式执行计划 2.a XML Generator,将步骤1输出的MEMO进行xml序列化 2. PDW Query Optimizer,memo中包含多个等价plans,并从单机统计信息角度计算了代价,这里枚举计算节点的数据分发方式,并计算分发代价,更新整个plan的代价信息,选择最佳 Data MovementData Movement Service(DMS)负责在所有node节点间转移数据。query在控制节点和数据节点上分布式执行时,就会需要在节点间移动数据。PDW使用临时表存储中间计算结果、接受其他节点发送的数据。在某些情况下,可以通过query重写的方式,将其下发到计算节点,然后将结果直接返回给客户端,此时,不需要走DMS了。个人理解:根据元数据,确认query涉及的数据在计算节点1上,那么改写query,增加query执行节点信息,然后下发,在计算节点1上执行,结果返回给客户端,不用建立临时表了。 DSQL plan的算子对于用户的sql query,PDW会创建并行执行plan(DSQL plan),DSQL plan包含如下类型的算子: SQL Operations:可以在一个或多个计算节点直接执行的算子,例如scan、sort等DMS Operations:在执行树上,将本步骤计算得到的临时数据,发送其他计算节点Temp table Operations:建立临时表,供后续生成中间结果、接收其他节点数据Return Operations:将数据发送给目标的算子查询执行模式PWD在执行查询计划时,没有采用pipeline模式,而是一次执行一个算子,这个算子可以在多个计算节点并行执行,例如scan。 论文没有给出这种设计的原因,个人理解,这种一次执行一个算子的方式要易于实现,另外,也易于做资源管控。从业务场景来看,大部分AP场景都是在夜间跑批,更注重稳定可靠,性能略有不足,也是可以接受的。毕竟,一旦因oom等资源问题业务中断,还需要重来,更加费时。 PWD查询优化实现SQL Server优化器增强图2所示的SQL Server组件,为支持PDW进行了增强,具体如下: 支持MEMO的XML序列化输出。编译了一个新的函数,负责请求优化器的Memo数据,类似于SQL Server中的"showplan XML"函数。当发出PDW编译请求后,SQL Server会以XML格式返回MEMO数据扩展SQL语法,以支持PDW。PDW的目标是与SQL Server完全兼容,因此,这个扩展仅限于针对特定的分布式执行策略的增加少量query hit。扩展优化器搜索空间,根据数据分布信息,生成一些与分布式查询执行相关的等价plans,特别是在join和union方面。SQL Server中的查询优化器采用了transformmation-based架构,即rules注册机制,这样可以在不对框架进行重大更改的情况下实现这些扩展。与基于成本的transform相关的一个基本问题是,这些transform是否会导致需要评估的替代方案的组合数量爆炸,以及它们是否会在查询优化的成本和SQL执行的成本之间提供权衡。SQL Server优化器使用了timeout机制,并不会生成所有可能的plans。在这些情况下,在MEMO中基于全局统计信息的可能winner的plans对所考虑的Search space有很大的影响。为了提升PDW查询优化的效率,尽量不穷举所有的备选plans,而是从备选plans中考虑table的数据分布信息以高效配置DMS算子,选择部分"优质plans",即“seed”plans。这个考虑数据分布的方式和interesting order类似,从上到下提出require distribution,从下向上提出provide distribution,进行匹配,不满足增加exchange,这个选种子plans时,尽量选择不需要增加exchange的候选plans。Plan Enumeration(枚举+剪枝)SQL Server优化器原来的搜索空间就很大,引入data movement(DMS)算子后,进一步增大了。除非query非常简单,否则原有的枚举算法已经不太适用了。本节,论文描述了一种bottom-up的搜索策略。目前,PDW QO使用了bottom-up的搜索策略,top-down的剪枝技术。伪代码如下:  PWDOptimizer方法对应于图2步骤4的QueryOptimizer: 将SQL Server发送过来的MEMO XML解析为PWD MEMO对象以bottom-up方式,应用MEMO的预处理rules,例如,修正一些分布式执行算子的cardinality estimation,例如partial/final aggregation,在单机节点上虽然枚举了出来但没有分布式的statistics,这个card是不准确的,需要校正以bottom-up方式,以PDW的分布式视角,对于group内的等价表达式进行合并,不是很理解???以top-down方式,提取每个group的intersting properties(扩展了System-R的interesting order,添加了distribution属性)//begin bottom-up 枚举 5.对MEMO中的每个group,以bottom-up的方式,枚举分布式计划 6.枚举步骤: a.枚举(基于数据分布属性):针对input group中所有可能expression,枚举本group内所有可能的分布式执行方式,生成新的group expression。例如,采用Shuffle、Broadcast等不同的数据分布方式,最终的代价是不同的。这个过程中,也会根据RBO规则,进行剪枝。 b.剪枝(基于代价):在group中添加expression时,即增加一个plan,对于每个interesting属性,保留一个总体最佳属性plan和本interesting属性最佳属性plan,考虑的都是以当前节点为root的plan。另外,每次向memo写入一个expression时,都会进行group内的剪枝。在一个group内,expressions(逻辑等价的plans)的最大值是interesting properties + 1。例如,对于order属性、distribute属性,最多保留3个plan。 7.Enforcer 步骤,增加物理算子的步骤,如果对于上层的require properties,下层的算子无法满足,则需要增加一个物理算子来满足,此时,也需要基于代价进行剪枝,方法同6.b。 //end bottom-up 剪枝 8.提取最优plan,从root group中获取最优的plan tree 9.对这个最优plan应用post-optimization rules,论文没有给出这个rules是什么,个人理解可能是topN之类的规则。 10.以bottom-up方式生成DSQL 11.对DSQL应用post-DSQL-generation rules 12.返回最终DSQL执行计划 Cost ModelPDW优化器的代价评估模型中计算了data movement算子的代价。 Cost Model假设从0开始建立代价评估模型是一个非常有挑战的工作。我们当前版本的成本模型力求简单性,同时努力确保高质量。当前版本的成本模型的范围是仅根据响应时间计算DMS算子的成本。考虑到这个目的,假设: DSQL step是自低向上按步骤一步一步执行的,非pipeline模式,也就是说下级算子执行完成后,将结果物化,然后发送给上级算子,上级算子才可以计算。因此,cost就是各个步骤的cost的累加值计算cost时,仅考虑本query的情况,不考虑并发query的影响。假设所有节点的硬件是相同的假设数据是均匀分布的,不考虑data skewDMS 算子类型DMS算子有7中类型,用于节点间数据传输: Shuffle Move(多对多) ,基于shuffle key的hash分片,将数据从计算节点分发到其他目标节点Partition Move(多对1),将每个计算节点存储的table分片数据发送到目标节点Control-Node Move,从控制节点向计算节点发送数据,一般是控制节点向计算节点发送复制表Boradcast Move,每个计算节点将数据发送给存储目标表数据的所有计算节点Trim Move,是复制表机制的一个简化,仅将元数据发送到对应计算节点Replicated broadcast,从1个compute node分发到所有compute nodeRemote copy to single node,从本地拉取远程数据,可以是已复制表的远程副本(来自控制节点或来自计算节点),也可以是分布式表的远程副本。上面定义的每个DMS算子都是由一个common runtime算子实现,DMS算子的成本将因正在实施的操作的不同而有所不同。 DMS算子代价DMS算子,总的来说可以分为Reader和Writer两种,其实就是从当前节点发送数据还是接收远端节点发来的数据,如下图 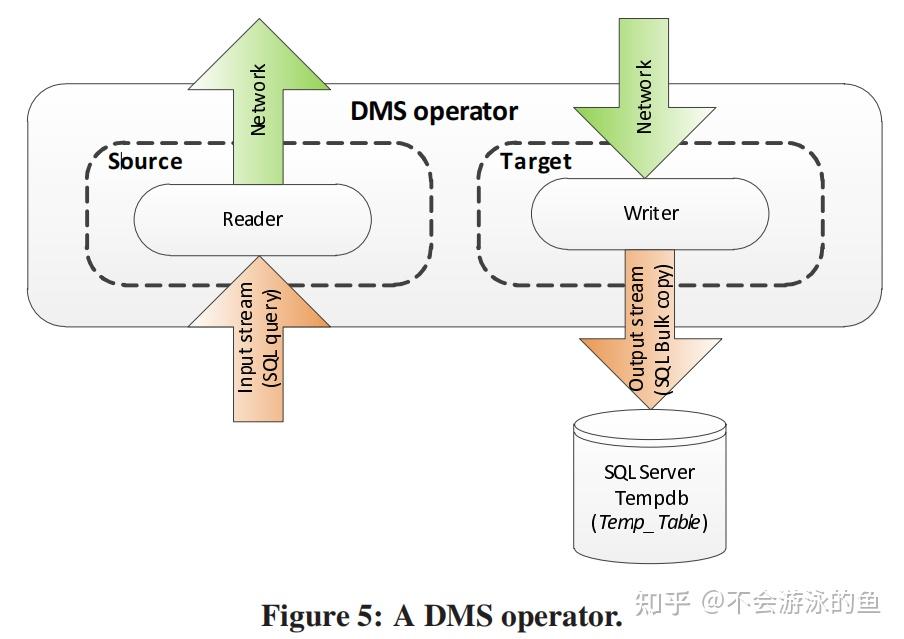 DMS算子分类:source component:负责将本节点数据发送给其他节点Creader:从本地节点读取数据,并打包写入bufferCnetwork:从buffer中通过网络发送数据Csource = max(Creader, Cnetwork),因为Creader, Cnetwork是异步的target component:从其他节点接收数据Cwriter:对通过网络接收到的数据进行解包,然后写入本地bufferCSQLBulkCpy:对于buffer中的数据,采用bulk copy的方式写入临时表Ctarget = max(Cwriter, CSQLBulkCpy) DMS算子分类:source component:负责将本节点数据发送给其他节点Creader:从本地节点读取数据,并打包写入bufferCnetwork:从buffer中通过网络发送数据Csource = max(Creader, Cnetwork),因为Creader, Cnetwork是异步的target component:从其他节点接收数据Cwriter:对通过网络接收到的数据进行解包,然后写入本地bufferCSQLBulkCpy:对于buffer中的数据,采用bulk copy的方式写入临时表Ctarget = max(Cwriter, CSQLBulkCpy)source类算子和target类算子是并行执行,因此, Cdms = max(Csource, Ctarget). 每个DMS算子的代价模型:Cxx = B * λ,B是操作处理的字节数,λ是不同操作对应的常量代价因子 引自:https://zhuanlan.zhihu.com/p/366434087 在这篇著名的paper[1]中,我们都看到这样一个结论:由于Cardinality Estimation通常具有很大的误差,导致cost model的精确性变得不那么重要。 这里PDW的设计者们也做出了类似的判断,认为精细的cost model会使得plan对于数据分布/统计信息/执行环境等的微小变化都更为敏感,反而不够robust,此外维护和调试成本也更高,因此这里每个Cxx的计算都非常简单:Cxx = B * λ,B是操作处理的字节数,λ是不同操作对应的常量代价因子,可以看到cost model保持了尽可能的简单。DSQL Generation当PDW生成查询计划后,需要将其转换成DSQL(含有分布式hit的扩展SQL)形式,这样才可以在各个计算节点执行。GreenPlum等其他MPP是发送operator tree给计算节点,由计算节点直接执行。PDW是发送SQL语句至计算节点。计算节点就是标准的DBMS实例,直接执行控制节点发来的SQL,DMS算子用于在不同节点上的DBMS实例之间传输数据。PDW的这种执行方式和MemSQL很相似。 执行DSQL Generation需要将operator tree转换为对应的SQL语句。PDW使用了微软的QRel programming框架实现这一步骤,如图6所示。 将PDW的物理执行计划转换为逻辑计划,RelOP tree基于ORel库,将RelOP tree转换为PIDMOD AST最终,PIDMOD脚本生成器根据这个AST生成T-SQL字符串,详细过程见文献《Unit-testing query transformation rules》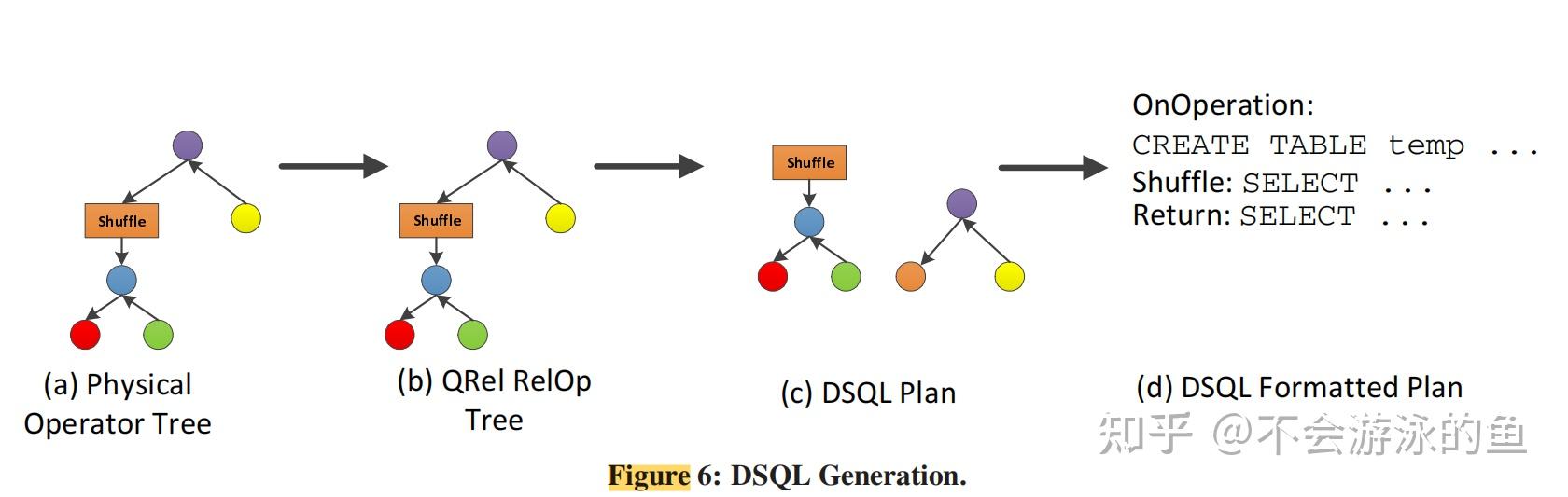 Example Examplequery: SELECT *FROM CUSTOMER C, ORDERS O WHERE C.C_CUSTKEY = O.O_CUSTKEY AND O.O_TOTALPRICE > 1000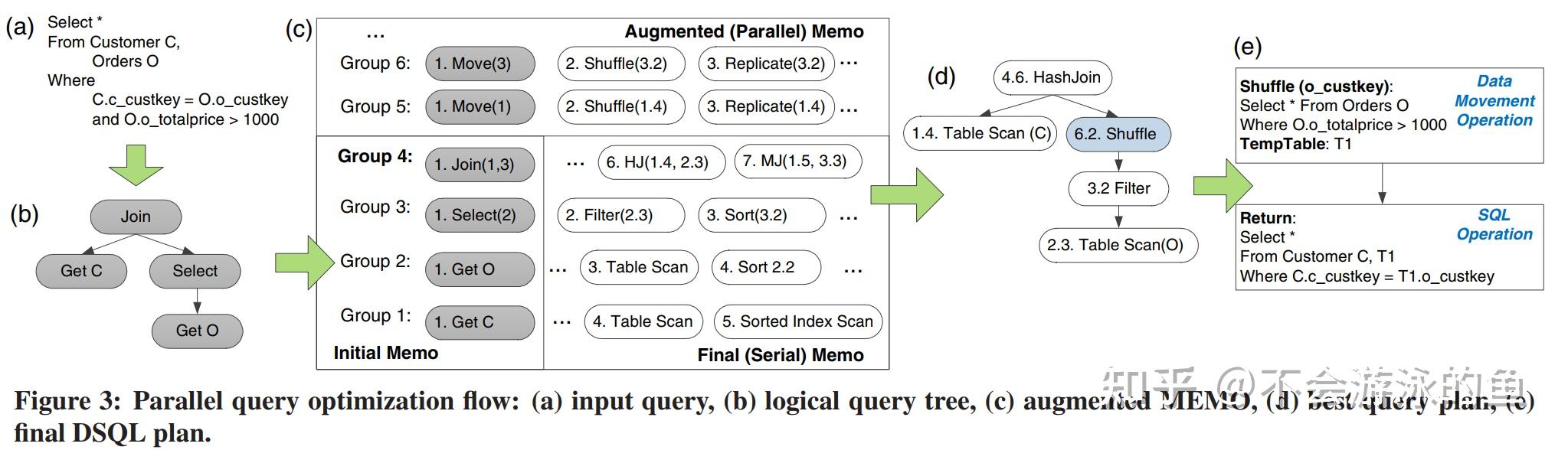 a.sql queryb.根据sql query生成的astc.Initial Memo,根据ast生成的初始memoc.Final(Serial) Memo,基于统计信息+RBO规则+CBO规则,但不考虑数据分布信息的Memo,可以理解为单机版的best planc.Augmented(Parallel)Memo,引入DMS算子(shuffle、boradcast等)后,枚举了新的分布式pland,从c中选出最佳plane.基于QRel programming框架,将d中的分布式执行plan转换为SQL语句,下发给计算节点执行,包括DMS operator和SQL operator。Shuffle(o_cuskey)语句,表示从Order表所在的节点中读取数据,按照o_cuskey进行hash分片,发送给o_cuskey分片对应的Customer节点,在Customer表的存储节点写入临时表T1;Return语句表示,Customer表的存储节点执行Customer和临时表T1的hashjion,结果在return给控制节点参考资料 a.sql queryb.根据sql query生成的astc.Initial Memo,根据ast生成的初始memoc.Final(Serial) Memo,基于统计信息+RBO规则+CBO规则,但不考虑数据分布信息的Memo,可以理解为单机版的best planc.Augmented(Parallel)Memo,引入DMS算子(shuffle、boradcast等)后,枚举了新的分布式pland,从c中选出最佳plane.基于QRel programming框架,将d中的分布式执行plan转换为SQL语句,下发给计算节点执行,包括DMS operator和SQL operator。Shuffle(o_cuskey)语句,表示从Order表所在的节点中读取数据,按照o_cuskey进行hash分片,发送给o_cuskey分片对应的Customer节点,在Customer表的存储节点写入临时表T1;Return语句表示,Customer表的存储节点执行Customer和临时表T1的hashjion,结果在return给控制节点参考资料梁辰:Query Optimization in Microsoft SQL Server PDW Unit-testing query transformation rules |
【本文地址】
今日新闻 |
推荐新闻 |