Streampark2.0整合flinkcdc实现数据实时同步到Hive |
您所在的位置:网站首页 › 1千万是多少个亿 › Streampark2.0整合flinkcdc实现数据实时同步到Hive |
Streampark2.0整合flinkcdc实现数据实时同步到Hive
|
背景 随着公司业务数据增长和对数据分析能力的增强。以往T+1/H+1的离线数据提供已经不能满足公司的业务需求。比如客户分配数据和线索数据,谁会希望分配的客户或线索几个小时后才会被跟进呢。不仅如此,千万级、亿级的大表同步问题也非常头疼。以往的小表(同步方案:业务低峰期度业务库)随着业务发展变成了千万级大变带来的慢SQL一直被DBA诟病。针对这类表目前还是只能申请只读实例进行同步,成本比较高。 下图所示是公司内部实时链路架构图  这个架构因为复杂度高、连路长出现了不少稳定性问题,导致数据会漏掉。特别是集群资源使用高峰期sparkstreaming会因为hbase写入压力触发反压机制,导致数据延迟甚至sparkstreaming程序宕机重启。另外一点是如果需要其它hive内部表和这类外部表做联合查询,还需要把外部表经过跑批任务,转换成内部表。性能差不说还繁琐。 问题大表同步难成本高实时性要求更高调研基于上述背景我们希望有一套技术体系可以解决至少其中的一个问题。如果能同时解决这两个问题那么就更好了。作为大数据工程师站在技术人的角度,首先还是要关注数据同步的问题,毕竟数据都不准实时性的价值也就无从谈起。经过一段时间的调研我们发现业界比较新颖的数据同步手段是通过Flink CDC进行。我们经过了一两周的时间在测试环境搭建了flink环境,在flink sql client中对flink+flinkcdc进行了功能测试。发现它完全符合我们的功能需求。这套方案的好处是: 简化了数据同步链路 容错和故障恢复。完善的checkpoint和savepoint机制支持 Exactly Once增量同步效率更高 容错和故障恢复。完善的checkpoint和savepoint机制支持 Exactly Once增量同步效率更高与此同时我们发现了这套方案带来的新问题,难道我要基于flink cdc再去整合?把它集成到公司数据中台上来吗?整合要考虑到监控、web可视化操作、学习flink java doc、任务管理等等。这些绝对是不小的工作量而且是摸着石头过河。希望借助一个平台能对flink的操作进行可视化操作并且对常用操作提供脚手架,能开箱即用。这时候我们发现Streamspark,并基于它快速完成了flink cdc任务的编辑、提交和日常管理。 技术方案最终为了解决大表同步难和实时性我们的方案是 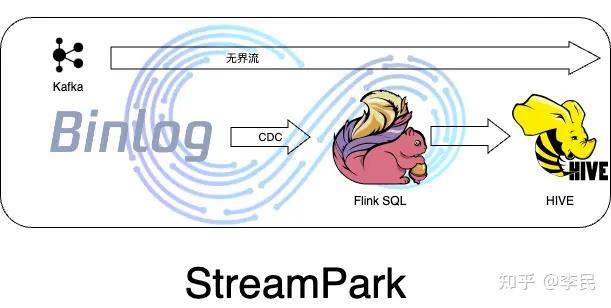 技术实施本地编译环境 技术实施本地编译环境如果要尝试RC版本或者其他Bata版本需要自己编译的话需要在本机具备以下条件 mysql5.7、jdk1.8、macos13.2.1高版本maven。作者本来使用的3.2.3版本结果提示版本太低,果断升级到3.8.7最新版如果是前后端一起编译需要安装npm和nodejs环境,根据提示安装即可编译请运行项目根目录下的bulid.sh文件,编译后的tar包在/dist下面。别再傻傻的mvn package然后到群里问为啥没有编译出来了[手动狗头]最后非常非常重要的一点,首次编译会下载堆依赖,比较慢。你最好准备一个梯子服务器环境Flink : 1.13.6Streampark : 2.0Ambari : 2.7HDP:3.1.4.0Java:1.8Linux : CentOS 7MySQL: 5.7 Step 1 : 安装Flink去官网下载flink安装包flink-1.13.6-bin-scala_2.11.tgz解压到/opt下flink环境还是比较简单,如果对此有疑问,请阅读官网帮助文档。这里着重说streampark Step 2 : 安装Streampark去官网下载Streampark安装包apache-streampark_2.11-2.0.0-incubating-bin.tar.gz解压到/opt下创建Streampark数据库到Mysql分别执行/opt/apache-streampark_2.11-2.0.0-incubating-bin/script/下的schema/mysql-schema.sql和data/mysql-data.sql添加mysql驱动(mysql8的用户可以忽略这一步)添加mysql5.7的驱动jar包到/opt/apache-streampark_2.11-2.0.0-incubating-bin/lib下Streampark2.0默认支持的是mysql8,在application-mysql.yml的配置文件中默认的mysql驱动地址是com.mysql.cj.jdbc.Driver.故:如果你的数据库和我一样是5.7版本,那你就要像我一样,添加5.7的驱动,并且修改驱动地址为com.mysql.jdbc.Driver。 这里在刷streampark脚本到mysql的时候可能会出现:mysql Index column size too large遇到这个问题,检查下你的mysql是不是5.7 。由于mysql5.7索引的长度限制,所以遇到这个问题的时候。请修改报错表主键和索引长度是255的字段,改成128。就这个mysql8的问题,作者可以在github上弄个FAQ,并且简单提供兼容mysql5.7的办法和配置文件修改方法。我司89个RDS实例只有5个mysql8的版本,说明mysql8在生产环境使用的并没有5.7多。当然,也许是我司个例。作者酌情考虑即可 修改StreamparkMysql配置和环境信息1、修改/opt/apache-streampark_2.11-2.0.0-incubating-bin/conf/application-mysql.yml填写对应的mysql账号密码和环境信息mysql5.7的用户注意修改driver-class-name为com.mysql.jdbc.Driver2、修改/opt/apache-streampark_2.11-2.0.0-incubating-bin/conf/application.yml以下几项着重检查,其它的配置视情况而定 server: port: 10000 #检查端口不要冲突。比如hive server的端口就是10000号端口 spring: profiles.active: mysql #改成mysql workspace: local: /opt/streampark_workspace #看情况修改 remote: hdfs://testclsuter/streampark #修改成自己环境下的hdfs地址修改/etc/profile环境变量 export HADOOP_CLASSPATH=`hadoop classpath` export HADOOP_HOME=/usr/hdp/3.1.4.0-315/hadoop #根据实际情况填写 export HADOOP_CONF_DIR=/etc/hadoop/conf #根据实际情况填写 export HIVE_HOME=$HADOOP_HOME/../hive export HBASE_HOME=$HADOOP_HOME/../hbase export HADOOP_HDFS_HOME=$HADOOP_HOME/../hadoop-hdfs export HADOOP_MAPRED_HOME=$HADOOP_HOME/../hadoop-mapreduce export HADOOP_YARN_HOME=$HADOOP_HOME/../hadoop-yarn启动Streampark [root@tabr1 bin] ./startup.sh默认账号密码:admin/streampark 登陆后的效果如下:  作者在使用过程中发现一个问题,在这个界面终止任务后。不知道出于什么原因在yarn上并没有停止掉,新用户在上线streampark后,一定要特别注意这点。最好是直接在flink管理界面终止,如果要做savepoint,那么在streampark上终止后在yarn上检查下,确认application结束了。后期如果要streampark到内部系统在这点上也需要多关注。 配置Flink环境  flink要和streampark安装在同一台机器。这里配置成功后才能在作业管理里面添加flinksql任务。作者因为好奇,在这里添加了不同版本的flink,发现这里居然没有删除功能。不能删除我不用的flink版本。我想sparkpark的作者一定是忙忘记了 Step 3 : CDC代码以及依赖CDC代码实例MySQL表结构:CREATE TABLE `alert_log` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `biz_type` int(11) NOT NULL COMMENT '业务类型,1:定时任务,2:数据表', ... `create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间', `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=860598 DEFAULT CHARSET=utf8;Hive表结构。提前创建,用户接收最终的binlog的数据: CREATE TABLE ods.kafka_hive_cdc_v3 ( `id` bigint, `biz_type` string, ... `create_time` string, `update_time` string, `type` string ) PARTITIONED BY (dt string, hr string) STORED AS parquet TBLPROPERTIES ( 'partition.time-extractor.timestamp-pattern'='$dt $hr:00:00', 'sink.partition-commit.trigger'='partition-time', 'sink.partition-commit.delay'='5 S', #数据刷入hdfs的时间间隔 'sink.partition-commit.watermark-time-zone'='Asia/Shanghai', #设置时区 'sink.partition-commit.policy.kind'='metastore,success-file', 'auto-compaction'='true', 'compaction.file-size'='5MB', 'sink.rolling-policy.file-size'='5MB', 'sink.rolling-policy.rollover-interval'='20s', 'sink.rolling-policy.check-interval'='10s' );Flink SQL代码: ### 读取binlog。先确认自己要配置的mysql是否开启了binlog row模式 CREATE TABLE test_mysql_alert_log_binlog_cdc_v3 ( `id` bigint, `biz_type` int, ... `create_time` STRING, `update_time` STRING, PRIMARY KEY(id) NOT ENFORCED ) WITH ( 'connector' = 'mysql-cdc', 'hostname' = '数据地址', # 修改 'port' = '3306', 'username' = '账号', # 修改 'password' = '密码', # 修改 'server-time-zone' = 'Asia/Shanghai', 'database-name' = '数据库', # 修改 'table-name' = 'alert_log', # 修改 'scan.startup.mode' = 'latest-offset' ); # 创建kafka表,用来接受binlog日志 # 请注意如果kafka集群没有开启自动创建topic功能,需要手动创建,命令如下: # ./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 5 --topic cdc_json_test_v3 CREATE TABLE test_kafka_alert_log_binlog_cdc_v3 ( `id` bigint, `biz_type` int, ... `create_time` STRING, `update_time` STRING ) WITH ( 'connector' = 'kafka', 'topic' = 'cdc_json_test_v3', # 修改。如果topic关闭的自动创建,需要手动新创建topic 'properties.group.id' = 'flink', # 修改group id 'scan.startup.mode' = 'latest-offset',# 可以不修改,根据自身情况而定 'properties.bootstrap.servers' = 'Kafka brokerServer的地址,多个用逗号隔开', # 修改 'format' = 'canal-json', 'canal-json.ignore-parse-errors'='true' ); # binlog写入kafka表。这一步完成后会在会占用一个Slot,开启一个类似sparkstreaming一样常驻任务在jobs中执行。 # 这时候可以使用`./kafka-console-consumer.sh --bootstrap-server brokerServer:port --topic cdc_json_test_v3`消费,看看数据有没有到kafka # 上面这些操作可以选择在flink sql client中先测试,测试过程中直接查询kafka表也可以查阅有没有数据流入 INSERT INTO test_kafka_alert_log_binlog_cdc_v3 SELECT * FROM test_mysql_alert_log_binlog_cdc_v3; # 转换kafka binlog格式。不然写不进hive。 #注意WATERMARK一定要设置,不然数据写入hdfs后hive metastore无法感知,从而没办法查询到数据 CREATE TABLE test_kafka_alert_log_binlog_cdc_convert3 ( `data` ARRAY, `type` string, `ts` as TO_TIMESTAMP(CONVERT_TZ(RTRIM(REGEXP_REPLACE(data[1]['create_time'],'T|Z',' ')), 'UTC', 'Asia/Shanghai'),'yyyy-MM-dd HH:mm:ss'), WATERMARK FOR ts AS ts - INTERVAL '5' SECOND ) WITH ( 'connector' = 'kafka', 'topic' = 'cdc_json_test_v3', 'properties.group.id' = 'flink_convert', 'scan.startup.mode' = 'earliest-offset', 'properties.bootstrap.servers' = 'kafka地址', 'format' = 'json' ); # 创建hive catalog。创建后flink就可以使用hive_catalog.库名.表名的方式访问hive数据了 CREATE CATALOG hive_catalog WITH ( 'type' = 'hive', 'default-database' = 'ods', 'hive-conf-dir' = '/usr/hdp/3.1.4.0-315/hive/conf' # 修改 ); # 数据从kafka写入hive insert into hive_catalog.ods.kafka_hive_cdc_v3 select id, biz_type, ... create_time, update_time, type, DATE_FORMAT(ts, 'yyyy-MM-dd'), DATE_FORMAT(ts, 'HH') from default_catalog.default_database.test_kafka_alert_log_binlog_cdc_convert3 cross join UNNEST(`data`) AS t(id, biz_type, ...,`create_time`,`update_time`); flinkSQL依赖这些依赖有一部分在flink lib下面就有,直接拿出来引用即可。由于不是所有的依赖都可以在仓库里面找到,并且还有一些修改过的jar包。生产环境建议自己在maven私服上传这些包,然后通过pom坐标引用会比较方便-rw-r--r--@ 1 limin staff 164K Nov 30 16:56 antlr-runtime-3.5.2.jar -rw-r--r--@ 1 limin staff 7.4M Feb 7 16:46 flink-connector-hive_2.11-1.13.6.jar -rw-r--r--@ 1 limin staff 90K Feb 4 2022 flink-csv-1.13.6.jar -rw-r--r--@ 1 limin staff 110M Feb 4 2022 flink-dist_2.11-1.13.6.jar -rw-r--r--@ 1 limin staff 145K Feb 4 2022 flink-json-1.13.6.jar -rw-r--r--@ 1 limin staff 7.4M May 7 2021 flink-shaded-zookeeper-3.4.14.jar -rw-r--r--@ 1 limin staff 47M Dec 12 16:10 flink-sql-connector-hive-3.1.2_2.11-1.13.6_update.jar -rw-r--r--@ 1 limin staff 3.5M Dec 14 15:20 flink-sql-connector-kafka_2.11-1.13.6.jar -rw-r--r--@ 1 limin staff 22M Nov 28 10:57 flink-sql-connector-mysql-cdc-2.3.0.jar -rw-r--r--@ 1 limin staff 39M Feb 4 2022 flink-table-blink_2.11-1.13.6.jar -rw-r--r--@ 1 limin staff 35M Feb 4 2022 flink-table_2.11-1.13.6.jar -rw-r--r--@ 1 limin staff 2.6M Dec 12 11:57 guava-28.0-jre.jar -rw-r--r--@ 1 limin staff 22M Feb 7 18:23 hadoop-client-runtime-3.1.1.3.1.4.0-315.jar -rw-r--r--@ 1 limin staff 1.6M Dec 12 17:16 hadoop-mapreduce-client-core-3.1.1.3.1.4.0-315.jar -rw-r--r--@ 1 limin staff 40M Nov 30 16:55 hive-exec-3.1.0.3.1.4.0-315.jar -rw-r--r--@ 1 limin staff 306K Nov 30 16:55 libfb303-0.9.3.jar -rw-r--r--@ 1 limin staff 203K Jan 13 2022 log4j-1.2-api-2.17.1.jar -rw-r--r--@ 1 limin staff 295K Jan 7 2022 log4j-api-2.17.1.jar -rw-r--r--@ 1 limin staff 1.7M Jan 7 2022 log4j-core-2.17.1.jar -rw-r--r--@ 1 limin staff 24K Jan 7 2022 log4j-slf4j-impl-2.17.1.jar注意:由于guava包冲突问题,使用过程中报 com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Ob...最小改动是仅替换Preconditions类即可。给它手动加入缺少的checkArgument(String,Object)方法 。修改后的flink-sql-connector-hive-3.1.2_2.11-1.13.6.jar增加了_update后缀。 Streampark上配置的效果。flink SQL代码如下图的方式填写即可。作业依赖可以填写maven坐标也可以自己上传jar包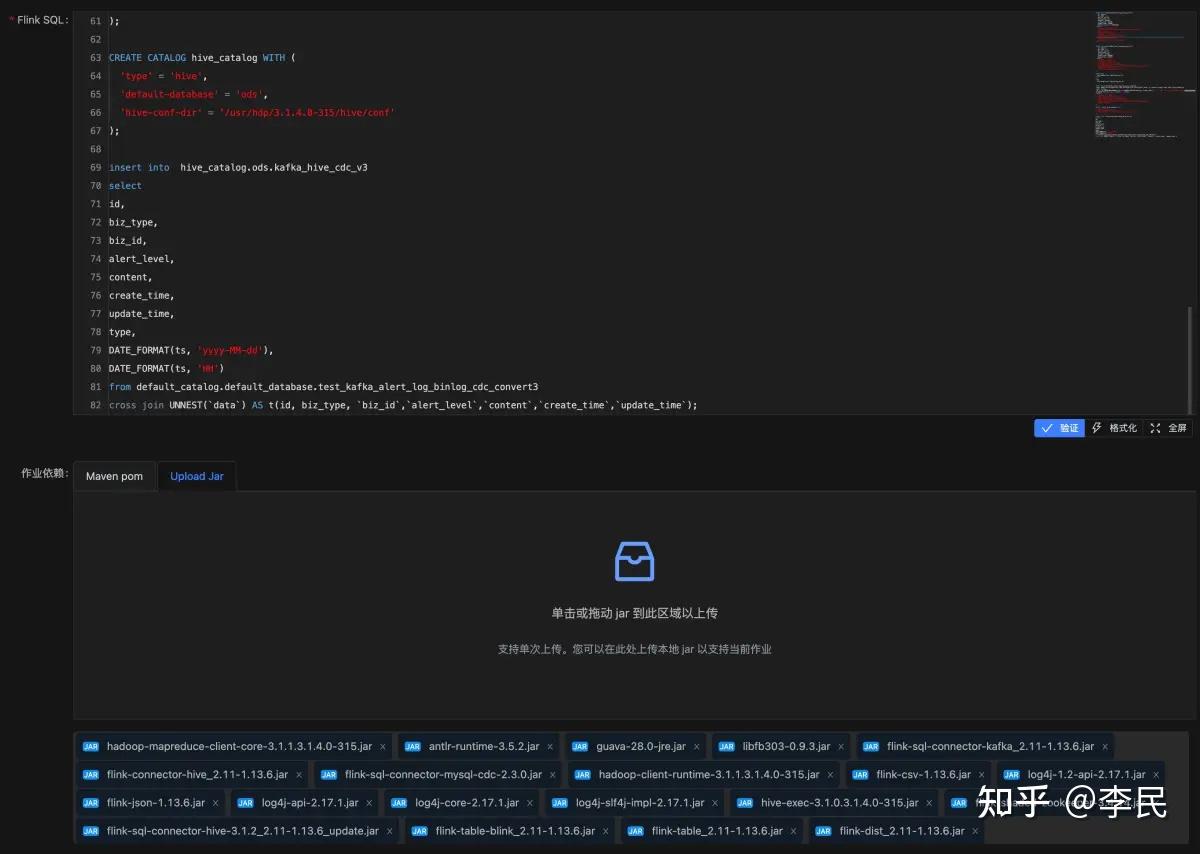 这里streampark考虑到每次做类似的作业时,jar包/pom反复上传的问题,做了一个复制能功能。可以克隆已经存在的任务。如果能开发一个资源管理工具,我们把不同类型的作业需要的资源进行归类,然后在创建作业的时候直接选择资源,可能灵活性便捷性会更高。 完成到这里就完成了flink sql cdc任务的创建。保存成功后可以在列表页面编译并运行了。在生产运行模式请选择application模式,资源独享,比较可靠。关键配置配置1:在streampark的动态参数中设置checkpoint模式并启用-Dexecution.checkpointing.interval=5000 -Dexecution.checkpointing.mode=EXACTLY_ONCE 配置2: WATERMARK一定要设置没注意看的同学请自己往回翻flink sql,仔细查看。WATERMARK如果不设置,数据写入hdfs后hive metastore无法感知,hive client查询不到数据。查阅源码发现,原因是因为flink在判断要不要通知hive metastore的时候,是根据WATERMARK的时间来判定要不要执行commit操作通知hive metastore。这个在flink官网有介绍,不过我想大部分人没什么耐性把文章仔细看一遍,所以这里特意指出来。 Step 4 : 生产环境配置注意点1、Streampark许多同学在尝试CDC的时候会直接使用flink sql client进行尝试,然后把代码通过streampark进行托管提交。那么client中用的set语法在streampark可能是不管用的,比如checkpoint配置。那么就需要在动态参数中通过 -D参数=值的方式设置 2、Flink以下几个项请根据建议直接配置在/opt/flink/conf/flink-conf.yaml文件中。比较常用 state.checkpoints.dir:checkpoints写出的目录位置,比如:hdfs://ns/flink/flink-checkpoints state.savepoints.dir:savepoints写出的目录位置,比如:hdfs://ns/flink/flink-checkpoints,一般与上面的值配置一致 execution.checkpointing.mode:检查点模式,默认值EXACTLY_ONCE,可选项AT_LEAST_ONCE execution.checkpointing.interval:checkpoint的时间间隔,单位毫秒,比如5000 state.checkpoints.num-retained:checkpoint保留的个数,默认值1,不过建议比如设置为3,防止想要恢复更久前的状态,或者最近的一个checkpoint被误删除等情况。需要设置在flink-conf.yml文件中 execution.checkpointing.externalized-checkpoint-retention:该配置项定义了在任务取消(cancel,注意不是job failed是主动的cancel)时如何清理外部化的检查点。一般我们会配置为RETAIN_ON_CANCELLATION,即cancel时保留检查点。而DELETE_ON_CANCELLATION则表示cancel任务时删除检查点,只有在任务失败时,才会被保留。需要注意的是,虽然execution.checkpointing.mode等参数可以在Streampark的动态参数中设置,但state.checkpoints.num-retained和execution.checkpointing.interval在动态参数中设置,是没有效果的(大坑)。需要直接写在flink-conf.yaml中。所以如果不是经常调的参数,建议直接配置在flink-conf.yaml中。这个要点对新手来说非常不友好,完全不懂那些在streampark中配置动态参数不生效。如果streampark能完全托管,或者明确哪些配置在哪里配,会更加容易上手。 效果与总结在生产环境试跑了1周左右的时间,数据几乎没有延迟(测试表每天大概1500w左右的更新量,延迟时间在checkpoint时间周期左右),也没有出现宕机的问题。checkpoin成功率100%。我们打算在季度末结合几个业务场景进行实战测试。streampark2.0全程使用下来要比streamx好用很多。streamx存在hive语法支持不全、jar包文件类型识别不全等一系列小问题,这些问题都需要自己编译修改源码暂时规避。但在2.0的版本做了修复,还有一系列新功能和其它问题修复。 强烈推荐使用2.0版本。 后续打算初次使用streampark到生产环境。前期打算就写一个可以自动生成cdc脚本的代码配合streampark在生产环境上先试运行,毕竟cdc的sql也太繁琐了,自己写真的很容易出错。后期结合streampark的api和公司自建的数据中台做集成。实现一站式开发的目的。一起期待我的后续文章吧 |
【本文地址】
今日新闻 |
推荐新闻 |