字符集及字符编码 |
您所在的位置:网站首页 › 1到100汉字编码表 › 字符集及字符编码 |
字符集及字符编码
|
字符编码问题一直深深困扰着我~无论是网页还是数据库抑或是单纯的文件字符流,总有各种奇怪的编码问题。之所以称之为奇怪其实主要还是因为我对于编码的知识了解太浅。近来深刻觉醒编码问题非解决不行,故将所阅读的资料内容概括整理如下。 字符编码与字符集一直以来我常常把字符编码和字符集混着说,而周围的人大多也都不区分它们的含义。不过真要较真的话,字符编码和字符集其实还是很有区别的。当然,从简单字符集的角度来说,按照惯例,人们认为字符集和字符编码是同义词,因为使用同样的标准来定义提供什么字符并且这些字符如何编码到一系列的代码单元(通常一个字符一个单元)。但是对于由统一码和通用字符集所构成的现代字符编码模型来说,这些概念之间有了细微的区别。它们将字符编码的概念分为:有哪些字符、它们的编号、这些编号如何编码成一系列的“码元”(有限大小的数字)以及最后这些单元如何组成八位字节流。区分这些概念的核心思想是建立一个能够用不同方法来编码的一个通用字符集。为了正确地表示这个模型需要更多比“字符集”和“字符编码”更为精确的术语表示。现代模型中所用的术语有字符集(Character Set)、编码字符集(CCS:Coded Character Set)、字符编码表(CEF:Character Encoding Form)、字符编码方案(CES:Character Encoding Scheme)等。这里的定义比较学术,大家感兴趣的可以自己查找维基百科,链接在本文后面的参考资料里可以找到。为了好记,我又找到一些比较通俗的关于字符集与字符编码区别的说法:字符集:字符的集合,规定了在这些集合里面有哪些字符。比如Unicode字符集,目标就是收纳了这个世界上所有语言的文字、符号等。字符编码:就是规定用一个字节还是用多个字节来存储一个字符,用固定的二进制码值表示某个字符。注意,字符集只是规定了有哪些字符,而最终决定采用哪些字符,每一个字符用多个字节表示等问题,则是由编码来决定的。像Unicode字符集的编码方式有很多,诸如UTF-8、UFT-16、UTF-32等。字符编码举例要解决编码问题,首先要明确究竟都有哪些编码,它们有什么样的特点,相互之间有何种关系。这样使用起来才能够有的放矢。在《Java编程思想》一书中,作者Bruce Eckel就是通过讲述文件输入输出流发展历史的方式清晰地展示了Java IO包中的各个stream、reader和writer该如何使用。我个人深感这是一种很好的学习方法,所以这里借鉴一下,也尽量按照字符编码的发展历史来介绍各个编码,这样我们就很容易明白这种编码为什么会诞生,以及它的特性了。首先先解释一下“字符”与“字节”的区别:字节(octet):是一个8位的物理存贮单元,取值范围一定是0~255。字符(character):是一个文化相关的符号,或说是一个语言上的符号,如“中”字就是一个字符。字符所占的大小由其编码方式解决,比如“中”在UTF-8中占3个字节(0xE4A8AD),而在GBK中,则占两个字节(0xD6D0)。1. 内码内码是操作系统内部所采用的字符编码,并不特指某种编码。比如早期的DOS采用的是ASCII编码,而现在的操作系统大都采用Unicode编码。2. ASCII码ASCII编码全称为American Standard Code for Information Interchange(美国信息交换标准代码)。对应的ISO 标准为ISO646标准。ASCII字符集:主要包括控制字符(回车键、退格、换行键等),可显示字符(英文大小写字符、阿拉伯数字和西文符号)。基本的ASCII字符集共有128个字符,其中有96个可打印字符,包括常用的字母、数字、标点符号等,另外还有32个控制字符。ASCII编码:将ASCII字符集转换为计算机可以接受的数字系统,使用7位(bits)表示一个字符,共128字符。每个ASCII码以1个字节(Byte)储存,从0(二进制:0000 0000)到127(二进制:0111 1111)代表不同的常用符号。例如大写A的ASCII码是65(二进制:0100 0001),小写a则是97(二进制:0110 0001)。虽然标准ASCII码是7位编码,但由于计算机基本处理单位为字节(1byte = 8bit),所以一般仍以一个字节来存放一个ASCII字符。每个字节中多余出来的一位(最高位)在计算机内部通常保持为0(在数据传输时可用作奇偶校验位)。ASCII码的缺点:只能显示26个基本拉丁字母、阿拉伯数字和英式标点符号,因此只能用于显示现代美国英语(而且在处理英语当中的外来词如naïve、café、élite等等时,所有重音符号都不得不去掉,即使这样做会违反拼写规则)。3. 扩展ASCII码(Extended ASCII)由于ASCII码只用了字节的七位,最高位并不使用,所以后来又将最高的一位也编入这套编码中,成为八位的扩展ASCII码。对应的标准为ISO2022标准,它规定了在保持与 ISO646兼容的前提下将ASCII字符集扩充为8位代码的统一方法。扩展ASCII字符集:ISO陆续制定了一批适用于不同地区的扩充ASCII字符集,每种扩充ASCII 字符集分别可以扩充128个字符,这些扩充字符的编码均为高位为1的8位代码(即十进制数128~255)。扩展ASCII码:为了表示更多的欧洲常用字符对ASCII进行了扩展,ASCII扩展字符集使用8位(bits)表示一个字符,共256字符。EASCII码的缺点:虽然解决了部份西欧语言的显示问题,但对更多其他语言依然无能为力。4. 区位码每个汉字或图形符号分别用两位的十进制区码(行码)和两位的十进制位码(列码)表示,不足的地方补0,组合起来就是区位码。比如“啊”的区位码是1601,写成16进制是0x10,0x01(二进制:00010000 00000001)。不过这和计算机广泛使用的ASCII编码冲突。为了兼容00-7f的 ASCII编码,我们在区位码的高、低字节上分别加上0xA0(二进制:10100000)。这样“啊”的编码就成为0xB0A1。我们将加过两个0xA0的编码也称为GB2312编码,虽然 GB2312的原文根本没提到这一点。5. 国标码把区位码按一定的规则转换成的二进制代码叫做信息交换码(简称国标码)。国标码共有汉字6763个(一级汉字,是最常用的汉字,按汉语拼音字母顺序排列,共3755个;二级汉字,属于次常用汉字,按偏旁部首的笔划顺序排列,共3008个),数字、字母、符号等682个,共7445个。汉字信息在计算机内部也是以二进制方式存放。由于汉字数量多,用一个字节的128种状态不能全部表示出来,因此在1980年我国颁布的《信息交换用汉字编码字符集——基本集》,即国家标准GB2312-80方案中规定用两个字节的十六位二进制表示一个汉字,每个字节都只使用低7位(与ASCII码相同), 即有128×128=16384种状态。由于ASCII码的34个控制代码在汉字系统中也要使用,为不致发生冲突,不能作为汉字编码,128除去34只剩 94种,所以汉字编码表的大小是94×94=8836,用以表示国标码规定的7445个汉字和图形符号。具体详见后面的GB2312(80)中。6. 机内码(汉字内码,内码)由于国标码不能直接存储在计算机内,为方便计算机内部处理和存储汉字,又区别于ASCII码,将国标码中的每个字节在最高位改设为1,这样就形成了在计算机内部用来进行汉字的存储、运算的编码叫机内码。内码既与国标码有简单的对应关系,易于转换,又与ASCII码有明显的区别,且有统一的标准(内码是惟一的)。7. 汉字外码(汉字输入码)无论是区位码或国标码都不利于输入汉字,为方便汉字的输入而制定的汉字编码,称为汉字输入码。汉字输入码属于外码。不同的输入方法,形成了不同的汉字外码。常见的输入法有以下几类:(1)按汉字的排列顺序形成的编码(流水码):如区位码;(2)按汉字的读音形成的编码(音码):如全拼、简拼、双拼等;(3)按汉字的字形形成的编码(形码):如五笔字型、郑码等;(4)按汉字的音、形结合形成的编码(音形码):如自然码、智能ABC。输入码在计算机中必须转换成机内码,才能进行存储和处理。8. 汉字字形码为了将汉字在显示器或打印机上输出,把汉字按图形符号设计成点阵图,就得到了相应的点阵代码(字形码)。汉字字库:全部汉字字形码的集合叫汉字字库。汉字字库可分为软字库和硬字库。软字库以文件的形式存放在硬盘上,现多用这种方式,硬字库则将字库固化在一个单独的存储芯片中,再和其它必要的器件组成接口卡,插接在计算机上,通常称为汉卡。显示字库:用于显示的字库叫显示字库。显示一个汉字一般采用16×16点阵或24×24点阵或48×48点阵。已知汉字点阵的大小,可以计算出存储一个汉字所需占用的字节空间。例:用16×16点阵表示一个汉字,就是将每个汉字用16行,每行16个点表示,一个点需要1位二进制代码,16个点需用16位二进制代码(即2个字节),共16行,所以需要16行×2字节/行=32字节,即16×16点阵表示一个汉字,字形码需用32字节。即:字节数=点阵行数×点阵列数/8。打印字库:用于打印的字库叫打印字库,其中的汉字比显示字库多,而且工作时也不像显示字库需调入内存。9. 代码页所谓代码页(code page)就是针对一种语言文字的字符编码。例如GBK的code page是CP936,BIG5的code page是CP950,GB2312的code page是CP20936。Windows中有缺省代码页的概念,即缺省用什么编码来解释字符。例如Windows的记事本打开了一个文本文件,里面的内容是字节流:BA、BA、 D7、D6。Windows应该去怎么解释它呢?是按照Unicode编码解释、还是按照GBK解释、还是按照BIG5解释,还是按照ISO-8859-1去解释?如果按GBK去解释,就会得到“汉字”两个字。按照其它编码解释,可能找不到对应的字符,也可能找到错误的字符。所谓“错误”是指与文本作者的本意不符,这时就产生了乱码。答案是Windows按照当前的缺省代码页去解释文本文件里的字节流。缺省代码页可以通过控制面板的区域选项设置。记事本的另存为中有一项ANSI,其实就是按照缺省代码页的编码方法保存。Windows的内码是Unicode,它在技术上可以同时支持多个代码页。只要文件能说明自己使用什么编码,用户又安装了对应的代码页,Windows就能正确显示,例如在HTML文件中就可以指定charset。有的HTML文件作者,特别是英文作者,认为世界上所有人都使用英文,在文件中不指定charset。如果他使用了0x80-0xff之间的字符,中文Windows又按照缺省的GBK去解释,就会出现乱码。这时只要在这个html文件中加上指定charset的语句,例如:如果原作者使用的代码页和ISO8859-1兼容,就不会出现乱码了。10. GB2312(80)GB2312是汉字字符集和编码的代号,中国国家标准简体中文字符集,中文全称为“信息交换用汉字编码字符集-基本集”,又称GB0,由中华人民共和国国家标准总局发布,一九八一年五月一日实施。GB 是“国标” 二字的汉语拼音缩写。 GB2312字符集:只收录简化字汉字,以及一般常用字母和符号,主要通行于中国大陆地区和新加坡等地。在这些编码里,我们还把数学符号、罗马希腊的字母、日文的假名们都编进去了,连在 ASCII 里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的”全角”字符,而原来在127号以下的那些就叫”半角”字符了。GB2312采用2个字节,共收录有7445个字符,其中简化汉字6763个,字母和符号682个。GB2312 将所收录的字符分为94个区,编号为01区至94区;每个区收录94个字符,编号为01位至94位。GB2312的每一个字符都由与其唯一对应的区号和位号所确定。例如:汉字“啊”,编号为16区01位。GB2312 字符集的区位分布表:
GB2312字符编码:GB2312是对 ASCII码的中文扩展,规定:一个小于127的字符的意义与原来相同,但两个大于127的字符连在一起时,就表示一个汉字,前面的一个字节(称之为高字节)从0xA1用到 0xF7(由字符的区号值加上32而形成),后面一个字节(低字节)从0xA1到0xFE(由字符的位号值加上32而形成),这样我们就可以组合出大约7000多个简体汉字了。GB2312原始编码是对所收录的每个字符都用两个字节(byte)表示。例如:汉字“啊”,编号为16区01位。它的高字节为16 + 32 = 48(0x30),低字节为01 + 32 = 33(0x21),合并而成的编码为0x3021。在区位号值上加32的原因大慨是为了避开低值字节区间。由于 GB2312 原始编码与 ASCII 编码的字节有重叠,现在通行的GB2312编码是在原始编码的两个字节上各加128修改而形成。例如:汉字“啊”,编号为16区01位。它的原始编码为0x3021,通行编码为0xB0A1(总体看其实是在区位码的高字节和低字节上各加上0xA0)。如果不另加说明,GB2312 常指这种修改过的编码。GB2312 字符集是Unicode字符集的一个子集。这也就是说,GB2312 所收录的每一个字符都收录在Unicode之中。但是GB2312编码和Unicode编码确没有什么相同之处。同一个汉字,它的GB2312编码和Unicode编码确毫不相同。例如:汉字“啊”,它的GB2312编码为0xB0A1,但是它的Unicode编码为0x554A。11. GBK微软利用GB 2312-80未使用的编码空间,收录GB 13000.1-93全部字符制定了GBK编码。根据微软资料,GBK是对GB2312-80的扩展,也就是CP936字码表(Code Page 936)的扩展(之前CP936和GB 2312-80一模一样),最早实现于Windows 95简体中文版。虽然GBK收录GB 13000.1-93的全部字符,但编码方式并不相同。GBK自身并非国家标准,只是曾由国家技术监督局标准化司、电子工业部科技与质量监督司公布为”技术规范指导性文件”。原始GB13000一直未被业界采用,后续国家标准GB18030技术上兼容GBK而非GB13000。GBK字符集:GBK也采用2个字节,包括了GB2312的所有内容,同时又增加了近20000个新的汉字(包括几乎所有的Big5中的繁体汉字)和符号。总共21003个字符。GBK字符编码:因为汉字太多,GB2312不够用,于是干脆不再要求低字节一定是127号之后的内码,只要第一个字节是大于127就固定表示这是一个汉字的开始,不管后面跟的是不是扩展字符集里的内容。结果扩展之后的编码方案被称为GBK 标准。12. GB18030全称为国家标准GB 18030-2005《信息技术 中文编码字符集》,是中华人民共和国现时最新的内码字集,是GB 18030-2000《信息技术 信息交换用汉字编码字符集 基本集的扩充》的修订版。与GB 2312-1980完全兼容,与GBK基本兼容,支持GB 13000及Unicode的全部统一汉字。GB18030字符集:为了加入几千个新的少数民族的字,GBK扩成了GB18030。GB18030字符编码:它采用了变长的编码方式,有1、2、4个字节的编码长度。1个字节编码与ASCII兼容,2个字节编码与GBK兼容,4个字节主要是收录了少数民族的文字等。GB18030现在是国家非手持/非嵌入式设备的强制性标准。所有的Unicode编码都可以转换为GB18030,而且GB18030除了兼容GBK以及Unicode的BMP部分外,其余的Unicode扩展平面和它的4字节扩展平面都是简单直接的映射。其具体映射关系的计算参见《GB18030编码研究以及GBK、GB18030与Unicode的映射》:[http://blog.csdn.net/fmddlmyy/archive/2008/04/13/2288312.aspx]GB 18030主要有以下特点:(1)与UTF-8相同,采用多字节编码,每个字可以由1个、2个或4个字节组成。(2)编码空间庞大,最多可定义161万个字符。(3) 支持中国国内少数民族的文字,不需要动用造字区。(4)汉字收录范围包含繁体汉字以及日韩汉字13. DBCSGB2312、GBK、GB18030等一系列汉字编码的标准被通称叫做“DBCS”(Double Byte Charecter Set 双字节字符集)。在DBCS系列标准里,最大的特点是两字节长的汉字字符和一字节长的英文字符并存于同一套编码方案里,因此他们写的程序为了支持中文处理,必须要注意字串里的每一个字节的值,如果这个值是大于127的,那么就认为一个双字节字符集里的字符出现了。14. BIG5BIG5字符集又称为大五码或五大码,是使用繁体中文(正体中文)社区中最常用的电脑汉字字符集标准,共收录13,060个汉字。BIG5字符集:它是台湾繁体字集,共包括国标繁体汉字13053个。中文码分为中文内码及交换码两类,Big5属中文内码,知名的中文交换码有CCCII、CNS11643。Big5虽普及于台湾、香港与澳门等繁体中文通行区,但长期以来并非当地的国家标准,而只是业界标准。倚天中文系统、Windows等主要系统的字符集都是以Big5为基准,但厂商又各自增加不同的造字与造字区,派生成多种不同版本。2003年,Big5被收录到CNS11643中文标准交换码的附录当中,取得了较正式的地位。这个最新版本被称为Big5-2003。BIG5字符编码:Big5码是一套双字节字符集,使用了双八码存储方法,以两个字节来安放一个字。第一个字节称为”高位字节”,第二个字节称为”低位字节”。”高位字节”使用了0x81-0xFE,”低位字节”使用了0x40-0x7E,及0xA1-0xFE。在Big5的分区中:
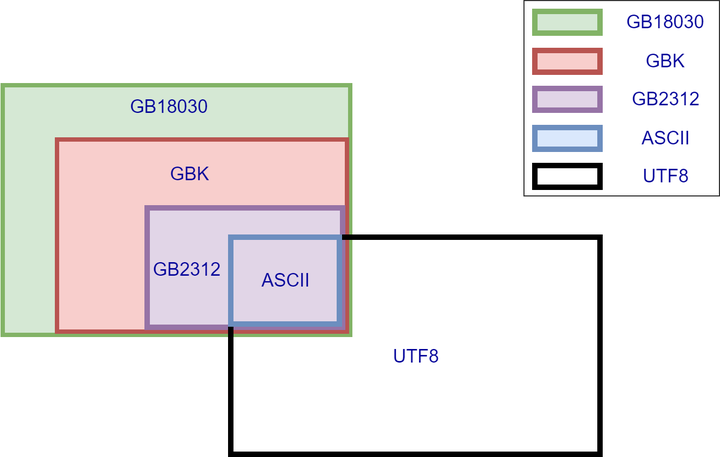
15. ANSIANSI是美国国家标准局的缩写,这里用来指代一类编码。使用2个字节来代表一个字符的各种汉字延伸编码方式,称为ANSI编码。比如,在简体中文系统下,ANSI编码代表GB2312编码;在日文操作系统下,ANSI编码代表JIS编码。非英文系的国家为了显示自家的文字,不得不一开始就得面对字符编码的问题,不同国家不同地区都创建了自己的编码标准。像是中国大陆是GB2312及后来的GBK,台湾是BIG5,日本是JIS。ASCII字符集,以及这些由此派生并兼容的字符集称为ANSI字符集。16. ISO-8859-1ISO 8859,全称ISO/IEC 8859,是国际标准化组织(ISO)及国际电工委员会(IEC)联合制定的一系列8位字符集的标准,现时定义了15个字符集。ISO 8859字符集:ASCII收录了空格及94个“可印刷字符”,足以给英语使用。但是,其他使用拉丁字母的语言(主要是欧洲国家的语言),都有一定数量的变音字母,故可以使用ASCII及控制字符以外的区域来储存及表示。除了使用拉丁字母的语言外,使用西里尔字母的东欧语言、希腊语、泰语、现代阿拉伯语、希伯来语等,都可以使用这个形式来储存及表示。* ISO 8859-1 (Latin-1) – 西欧语言;* ISO 8859-2 (Latin-2) – 中欧语言;* ISO 8859-3 (Latin-3) – 南欧语言。世界语也可用此字符集显示;* ISO 8859-4 (Latin-4) – 北欧语言;* ISO 8859-5 (Cyrillic) – 斯拉夫语言;* ISO 8859-6 (Arabic) – 阿拉伯语;* ISO 8859-7 (Greek) – 希腊语;* ISO 8859-8 (Hebrew) – 希伯来语(视觉顺序);* ISO 8859-8-I – 希伯来语(逻辑顺序);* ISO 8859-9 (Latin-5 或 Turkish) – 它把Latin-1的冰岛语字母换走,加入土耳其语字母;* ISO 8859-10 (Latin-6 或 Nordic) – 北日耳曼语支,用来代替Latin-4;* ISO 8859-11 (Thai) – 泰语,从泰国的 TIS620 标准字集演化而来;* ISO 8859-13 (Latin-7 或 Baltic Rim) – 波罗的语族;* ISO 8859-14 (Latin-8 或 Celtic) – 凯尔特语族;* ISO 8859-15 (Latin-9) – 西欧语言,加入Latin-1欠缺的法语及芬兰语重音字母,以及欧元符号;* ISO 8859-16 (Latin-10) – 东南欧语言。主要供罗马尼亚语使用,并加入欧元符号;很明显,iso8859-1编码表示的字符范围很窄,无法表示中文字符。但是,由于是单字节编码,和计算机最基础的表示单位一致,所以很多时候,仍旧使用iso8859-1编码来表示。而且在很多协议上,默认使用该编码。ISO 8859字符编码:我们知道ASCII码是从0x00(二进制:0000 0000)到0x7F(二进制:0111 1111),也就是还有1位没有用到,ISO 8859-1就是在空置的0xA0-0xFF(二进制:1010 0000-1111 1111)的范围内,加入192个字母及符号,藉以供使用变音符号的拉丁字母语言使用。所以ISO 8859-1又称Latin-1。17. Unicode(统一码、万国码、单一码)全称为Universal Multiple-Octet Coded Character Set,简称UCS(通用字符集-Universal Character Set)。历史上存在两个独立的尝试创立单一字符集的组织,即国际标准化组织(ISO)和多语言软件制造商组成的统一码联盟(http://www.unicode.org)。前者开发的ISO/IEC 10646项目,后者开发的统一码项目。1991年前后,两个项目的参与者都认识到,世界不需要两个不兼容的字符集。于是,它们开始合并双方的工作成果,并为创立一个单一编码表而协同工作。从Unicode 2.0开始,Unicode采用了与ISO 10646-1相同的字库和字码;ISO也承诺,ISO 10646将不会替超出U+10FFFF的UCS-4编码赋值,以使得两者保持一致。两个项目仍都存在,并独立地公布各自的标准。但统一码联盟和ISO/IEC JTC1/SC2都同意保持两者标准的码表兼容,并紧密地共同调整任何未来的扩展。在发布的时候,Unicode一般都会采用有关字码最常见的字型,但ISO 10646一般都尽可能采用Century字型。Unicode的编码方式与ISO 10646的通用字符集(UCS)概念相对应,目前的用于实用的Unicode版本对应于UCS-2,使用16位的编码空间。也就是每个字符占用2个字节,总共可以组合出65535个不同的字符,这大概已经可以覆盖世界上所有文化的符号。实际上目前版本的Unicode尚未填满这16位编码,保留了大量空间作为特殊使用或将来扩展。如果还不够也没有关系,ISO已经准备了UCS-4方案,说简单了就是四个字节来表示一个字符,这样我们就可以组合出21亿个不同的字符出来(最高位有其他用途)。由ISO制定的ISO 10646(或称ISO/IEC 10646)标准所定义的字符编码方式,采用4字节编码。UCS包含了已知语言的所有字符。除了拉丁语、希腊语、斯拉夫语、希伯来语、阿拉伯语、亚美尼亚语、格鲁吉亚语,还包括中文、日文、韩文这样的象形文字,UCS还包括大量的图形、印刷、数学、科学符号。* UCS-2: 与Unicode的2byte编码基本一样;* UCS-4: 4byte编码, 目前是在UCS-2前加上2个全0的byte。ISO就直接规定必须用两个字节,也就是16位来统一表示所有的字符,对于ASCII里的那些“半角”字符,Unicode保持其原编码不变,只是将其长度由原来的8位扩展为16位,而其他文化和语言的字符则全部重新统一编码。由于“半角”英文符号只需要用到低8位,所以其高8位永远是0,因此这种大气的方案在保存英文文本时会多浪费一倍的空间。Unicode 字符集收录了这世界上所有的文字符号和特殊符号。对于每一个符号都定义了一个值,称为代码点(code point)。代码点可以用2个字节表示(UCS-2),也可以用4个字节(UCS-4编码)。Unicode在制订时没有考虑与任何一种现有的编码方案保持兼容,这使得GBK与Unicode在汉字的内码编排上完全是不一样的,没有一种简单的算术方法可以把文本内容从Unicode编码和另一种编码进行转换,这种转换必须通过查表来进行。18. UTF编码UCS编码虽然定义了每个代码点的编码方式,但是没规定如何传输和存储。比如,在UCS-2码中,英文符号是在ACSII码的前面加上一个0 byte,像“A”的ASCII码 0x41,在UCS码中就是0x0041,这样,对于英文系统来讲会出现大量的0 byte,造成不必要的浪费。而且容易存在对现在的ASCII码不兼容的问题。所以这个重担就落在了UTF编码身上。于是面向传输的众多UTF(UCS Transfer Format)标准出现了。顾名思义,UTF8就是每次8个位传输数据,而UTF16就是每次16个位,只不过为了传输时的可靠性,从Unicode到UTF时并不是直接的对应,而是要通过一些算法和规则来转换。(1)UTF-8(Unicode Transformation Format – 8-bit)UTF-8是一种针对Unicode的可变长度字符编码(定长码),也是一种前缀码。它可以用来表示Unicode标准中的任何字符,且其编码中的第一个字节仍与ASCII兼容,这使得原来处理ASCII字符的软件无需或只需做少部份修改,即可继续使用。因此,它逐渐成为电子邮件、网页及其他存储或传送文字的应用中,优先采用的编码。互联网工程工作小组(IETF)要求所有互联网协议都必须支持UTF-8编码。UTF-8使用一至四个字节为每个字符编码:* 128个US-ASCII字符只需一个字节编码(Unicode范围由U+0000至U+007F)。*带有附加符号的拉丁文、希腊文、西里尔字母、亚美尼亚语、希伯来文、阿拉伯文、叙利亚文及它拿字母则需要二个字节编码(Unicode范围由U+0080至U+07FF)。* 其他基本多文种平面(BMP)中的字符(这包含了大部分常用字)使用三个字节编码。*其他极少使用的Unicode辅助平面的字符使用四字节编码。在处理经常会用到的ASCII字符方面非常有效。在处理扩展的拉丁字符集方面也不比UTF-16差。对于中文字符来说,比UTF-32要好。同时,UTF-8以字节为编码单元,由位操作的天性使然,使用UTF-8不再存在字节顺序的问题了。一份以utf-8编码的文档在不同的计算机之间是一样的比特流。总体来说,在Unicode字符串中不可能由码点数量决定显示它所需要的长度,或者显示字符串之后在文本缓冲区中光标应该放置的位置;组合字符、变宽字体、不可打印字符和从右至左的文字都是其归因。所以尽管在UTF-8字符串中字符数量与码点数量的关系比UTF-32更为复杂,在实际中很少会遇到有不同的情形。UTF-8的优点:*UTF-8是ASCII的一个超集。因为一个纯ASCII字符串也是一个合法的UTF-8字符串,所以现存的ASCII文本不需要转换。为传统的扩展ASCII字符集设计的软件通常可以不经修改或很少修改就能与UTF-8一起使用。*使用标准的面向字节的排序例程对UTF-8排序将产生与基于Unicode代码点排序相同的结果。(尽管这只有有限的有用性,因为在任何特定语言或文化下都不太可能有仍可接受的文字排列顺序。)*UTF-8和UTF-16都是可扩展标记语言文档的标准编码。所有其它编码都必须通过显式或文本声明来指定。*任何面向字节的字符串搜索算法都可以用于UTF-8的数据(只要输入仅由完整的UTF-8字符组成)。但是,对于包含字符记数的正则表达式或其它结构必须小心。* UTF-8字符串可以由一个简单的算法可靠地识别出来。就是,一个字符串在任何其它编码中表现为合法的UTF-8的可能性很低,并随字符串长度增长而减小。举例说,字符值C0,C1,F5至FF从来没有出现。为了更好的可靠性,可以使用正则表达式来统计非法过长和替代值(可以查看W3 FAQ: Multilingual Forms上的验证UTF-8字符串的正则表达式)。UTF-8的缺点:* 因为每个字符使用不同数量的字节编码,所以寻找串中第N个字符是一个O(N)复杂度的操作,即,串越长,则需要更多的时间来定位特定的字符。同时,还需要位变换来把字符编码成字节,把字节解码成字符。(2)UTF-16(Unicode Transformation Format – 16-bit)UTF-16以两个字节为编码单元。在解释一个UTF-16文本前,首先要弄清楚每个编码单元的字节序。Unicode规范中推荐的标记字节顺序的方法是BOM(即字节顺序标记-Byte Order Mark)。在UCS编码中有一个叫做“ZERO WIDTH NO-BREAK SPACE”的字符,它的编码是FEFF。而FFFE在UCS中是不存在的字符,所以不应该出现在实际传输中。UCS规范建议我们在传输字节流前,先传输字符”ZERO WIDTH NO-BREAK SPACE”。这样如果接收者收到FEFF,就表明这个字节流是Big-Endian的;如果收到FFFE,就表明这个字节流是Little-Endian的。因此字符“ZERO WIDTH NO-BREAK SPACE”又被称作BOM。Windows就是使用BOM来标记文本文件的编码方式的。UTF-16将0–65535范围内的字符编码成2个字节,如果真的需要表达那些很少使用的”星芒层(astral plane)”内超过这65535范围的Unicode字符,则需要使用一些诡异的技巧来实现。UTF-16编码最明显的优点是它在空间效率上比UTF-32高两倍,因为每个字符只需要2个字节来存储(除去65535范围以外的),而不是UTF-32中的4个字节。并且,如果我们假设某个字符串不包含任何星芒层中的字符,那么我们依然可以在常数时间内找到其中的第N个字符,直到它不成立为止这总是一个不错的推断。其编码方法是:*如果字符编码U小于0x10000,也就是十进制的0到65535之内,则直接使用两字节表示;* 如果字符编码U大于0x10000,由于UNICODE编码范围最大为0x10FFFF,从0x10000到0x10FFFF之间共有0xFFFFF个编码,也就是需要20个bit就可以标示这些编码。用U’表示从0-0xFFFFF之间的值,将其前 10 bit作为高位和16 bit的数值0xD800进行 逻辑or 操作,将后10 bit作为低位和0xDC00做逻辑or 操作,这样组成的 4个byte就构成了U的编码。(3)UTF-32(Unicode Transformation Format – 32-bit)使用4字节的数字来表达每个字母、符号,或者表意文字(ideograph),每个数字代表唯一的至少在某种语言中使用的符号的编码方案,称为UTF-32。UTF-32又称UCS-4,是一种将Unicode字符编码的协定,对每个字符都使用4字节。就空间而言,是非常没有效率的。但这种方法有其优点,最重要的一点就是可以在常数时间内定位字符串里的第N个字符,因为第N个字符从第4×Nth个字节开始。虽然每一个码位使用固定长定的字节看似方便,它并不如其它Unicode编码使用得广泛。常用软件的默认字符集及其查看方法(1)window下面保存记事本的文本字符集编码为:系统编码GBK;(2)linux下面的默认字符集编码查看方法:/etc/sysconfig/i18n;(3)利用cpdetector第三方包可以判断文件或者流的编码;(4)查询oracle的默认字符集编码方法:select userenv(‘language’) from dual;(5)早期操作系统的内码是与语言相关的。现在的Windows在内部统一使用Unicode,然后用代码页适应各种语言;(6)C、C++、Python2内部字符串都是使用当前系统默认编码;(7)Python3、Java内部字符串用Unicode保存;(8)Ruby有一个内部变量$KCODE用来表示可识别的多字节字符串的编码,变量值为”EUC” “SJIS” “UTF8″ “NONE”之一。$KCODE的值为”EUC”时,将假定字符串或正则表达式的编码为EUC-JP。同样地,若为”SJIS”时则认定为Shift JIS。若为”UTF8″时则认定为UTF-8。若为”NONE”时,将不会识别多字节字符串。在向该变量赋值时,只有第1个字节起作用,且不区分大小写字母。”e” “E” 代表 “EUC”,”s” “S” 代表 “SJIS”,”u” “U” 代表 “UTF8″,而”n” “N” 则代表 “NONE”。默认值为”NONE”。即默认情况下Ruby把字符串当成单字节序列来处理;(9)ultraedit在默认情况下是把utf-8转换为unicode编码,你看到的是unicode编码,如果你想看到真正的utf-8编码,那么在ultraedit中,做如下操作File—>conversions—>unicode/asc2/utf-8 to utf-8(asc2 editing)关于字符集及字符编码的问题这次先总结到这里,下次将对Java等字符编码进行进一步分析。 参考资料(1)维基百科-字符编码(2)《计算机编码知识——区位码、国标码、机内码、输入码、字形码》(3)《计算机内码与外码的区别》(4)《和荣笔记- GB2312 字符集与编码对照表》(5)《说说字符集和编码》(6)《编码简介》(7)《深入了解字符集和编码》(8)吴秦 《字符集和字符编码(Charset & Encoding)》 字符集、字符编码、乱码问题相关知识总结计算机在存储和传输文件信息(图片,文档,音频,视频等)的过程中,都是使用二进制的比特流形式。 所以要保持文件信息,就需要把文件信息按一定的规则转成二进制的比特流进行存储。 要查看文件信息,计算机也需要把拿到的文件信息(二进制比特流)按一定的规则转成我们能识别的东西。 这里所说的规则,即指编码和解码方式。 当把原始文件转成二进制比特流的编码方式和把二进制比特流转成文件的解码方式不兼容的情况下,就会出现乱码。 下面介绍字符集,字符编码。 字符集:是多个字符的集合。字符是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。 字符集对应到生活中就是对某种语言的称呼,如英语、日语、汉语等。 字符集规定了某个字符对应的二进制数值存放方式(编码)和某串二进制数值代表了哪个字符(解码)的转换关系。 那么为什么有很多种不相同的字符集呢? 就像世界上有不同的语言,不同地区或组织在最初制定字符集的时候,并不会意识到这将会是以后全球普适的准则,或者对于自身利益的考虑,就产生了那么多具有相同效果但又不相互兼容的标准了。 字符编码:是一套法则,使用该法则能够将字符集合中的每个字符与计算机能识别的一个二进制数值进行一一配对。 对于一个字符集来说,要正确编码解码一个字符需要三个关键元素:字库表、字符集、字符编码。 字库表是一个相当于所有可读或者可显示字符的数据库,字库表决定了整个字符集能够展现表示的所有字符的范围。 字符集,即用一个编码值code point来表示一个字符在字库中的位置。 每个字符在字库表中都有唯一的序号,为什么不把该唯一序号作为存储内容,却还要把该字符通过字符编码转成另外一种格式呢? 这是因为统一字库表的目的是为了能够涵盖世界上所有的字符,但实际使用过程中会发现真正用的上的字符相对整个字库表来说比例非常低。如果把每个字符都用字库表中的序号来存储的话,每个字符就需要3个字节(这里以Unicode字库为例),这样对于原本用仅占一个字符的ASCII编码的英语地区国家显然是一个额外成本(存储体积是原来的三倍)。于是就出现了UTF-8这样的变长编码。在UTF-8编码中原本只需要一个字节的ASCII字符,仍然只占一个字节。而像中文及日语这样的复杂字符就需要2个到3个字节来存储。 我们平常接触到的字符集有下面几种: 1.ASCII 字符集 计算机刚出现的时候,主要在西方国家应用,当时的字符集,ASCII 字符集主要用于显示现代英语和其他西欧语言。 对应于ASCII编码,用一个字节表示一个字符。 2.GB2312字符集 中国国家标准总局发布了主要用于表示简体中文的字符集,GB2312字符集。 对应于GB2312编码,用两个字节表示一个字符。 3.GBK字符集 因为GB2312并不能处理一些罕用字等,又出现了GBK字符集。GBK是从GB2312扩展而来,兼容GB2312。 对应于GBK编码,用两个字节表示一个字符。 4.BIG5字符集 台湾的多个组织共同发布了主要用于表示繁体中文的字符集,BIG5字符集。 对应于BIG编码,用两个字节表示一个字符。 5.Unicode字符集 Unicode 学术学会机构制订的Unicode字符集,收录了多种语言的字符并设定了统一且唯一的二进制码,支持现今世界各种不同语言的书面文本的交换、处理及显示。 Unicode字符集有多种字符编码方式:UTF-32编码 / UTF-16编码 / UTF-8编码。 UTF-32:每个字符都使用四个字节表示一个字符。 UTF-16:将0–65535范围内的字符都使用两个字节表示一个字符,65535范围外的字符用其他技巧 UTF-8:是一种可变长度的字符编码,也是一种前缀码。它可以用来表示Unicode标准中的任何字符,且与ASCII兼容,用一至四个字节为每个字符进行编码。(中文一般用三个字节进行编码) Unicode(UTF-8, UTF-16)令人混淆的概念 为啥需要Unicode我们知道计算机其实挺笨的,它只认识0101这样的字符串,当然了我们看这样的01串时肯定会比较头晕的,所以很多时候为了描述简单都用十进制,十六进制,八进制表示.实际上都是等价的,没啥太多不一样.其他啥文字图片之类的其他东东计算机不认识.那为了在计算机上表示这些信息就必须转换成一些数字.你肯定不能想怎么转换就怎么转,必须得有定些规则.于是刚开始的时候就有ASCII字符集(American Standard Code for Information Interchange, "美国信息交换标准码),它使用7 bits来表示一个字符,总共表示128个字符,我们一般都是用字节(byte,即8个01串)来作为基本单位.那么怎么当用一个字节来表示字符时第一个bit总是0,剩下的七个字节就来表示实际内容.后来IBM公司在此基础上进行了扩展,用8bit来表示一个字符,总共可以表示256个字符.也就是当第一个bit是0时仍表示之前那些常用的字符.当为1时就表示其他补充的字符. 英文字母再加一些其他标点字符之类的也不会超过256个.一个字节表示主足够了.但其他一些文字不止这么多 ,像汉字就上万个.于是又出现了其他各种字符集.这样不同的字符集交换数据时就有问题了.可能你用某个数字表示字符A,但另外的字符集又是用另外一个数字表示A.这样交互起来就麻烦了.于是就出现了Unicode和ISO这样的组织来统一制定一个标准,任何一个字符只对应一个确定的数字.ISO取的名字叫UCS(Universal Character Set),Unicode取的名字就叫unicode了. 总结起来为啥需要Unicodey就是为了适应全球化的发展,便于不同语言之间的兼容交互,而ASCII不再能胜任此任务了. Unicode详细介绍1.容易产生后歧义的两字节 unicode的第一个版本是用两个字节(16bit)来表示所有字符 .实际上这么说容易让人产生歧义,我们总觉得两个字节就代表保存在计算机中时是两个字节.于是任何字符如果用unicode表示的话保存下来都占两个字节.其实这种说法是错误的. 其实Unicode涉及到两个步骤,首先是定义一个规范,给所有的字符指定一个唯一对应的数字,这完全是数学问题,可以跟计算机没半毛钱关系.第二步才是怎么把字符对应的数字保存在计算机中,这才涉及到实际在计算机中占多少字节空间. 所以我们也可以这样理解,Unicode是用0至65535之间的数字来表示所有字符.其中0至127这128个数字表示的字符仍然跟ASCII完全一样.65536是2的16次方.这是第一步.第二步就是怎么把0至65535这些数字转化成01串保存到计算机中.这肯定就有不同的保存方式了.于是出现了UTF(unicode transformation format),有UTF-8,UTF-16. 2.UTF-8 与UTF-16的区别 UTF-16比较好理解,就是任何字符对应的数字都用两个字节来保存.我们通常对Unicode的误解就是把Unicode与UTF-16等同了.但是很显然如果都是英文字母这做有点浪费.明明用一个字节能表示一个字符为啥整两个啊. 于是又有个UTF-8,这里的8非常容易误导人,8不是指一个字节,难道一个字节表示一个字符?实际上不是.当用UTF-8时表示一个字符是可变的,有可能是用一个字节表示一个字符,也可能是两个,三个..反正是根据字符对应的数字大小来确定. 于是UTF-8和UTF-16的优劣很容易就看出来了.如果全部英文或英文与其他文字混合,但英文占绝大部分,用UTF-8就比UTF-16节省了很多空间.而如果全部是中文这样类似的字符或者混合字符中中文占绝大多数.UTF-16就占优势了,可以节省很多空间.另外还有个容错问题,等会再讲 看的有点晕了吧,举个例子.假如中文字"汉"对应的unicode是6C49(这是用十六进制表示,用十进制表示是27721为啥不用十进制表示呢?很明显用十六进制表示要短点.其实都是等价的没啥不一样.就跟你说60分钟和1小时一样.).你可能会问当用程序打开一个文件时我们怎么知道那是用的UTF-8还是UTF-16啊.自然会有点啥标志,在文件的开头几个字节就是标志. EF BB BF 表示UTF-8 FE FF 或者 FF FE 表示UTF-16. 用UTF-16表示"汉" 假如用UTF-16表示的话就是01101100 01001001(共16 bit,两个字节).程序解析的时候知道是UTF-16就把两个字节当成一个单元来解析.这个很简单. 用UTF-8表示"汉" 用UTF-8就有复杂点.因为此时程序是把一个字节一个字节的来读取,然后再根据字节中开头的bit标志来识别是该把1个还是两个或三个字节做为一个单元来处理. 0xxxxxxx,如果是这样的01串,也就是以0开头后面是啥就不用管了XX代表任意bit.就表示把一个字节做为一个单元.就跟ASCII完全一样. 110xxxxx 10xxxxxx.如果是这样的格式,则把两个字节当一个单元 1110xxxx 10xxxxxx 10xxxxxx 如果是这种格式则是三个字节当一个单元. 这是约定的规则.你用UTF-8来表示时必须遵守这样的规则.我们知道UTF-16不需要用啥字符来做标志,所以两字节也就是2的16次能表示65536个字符. 而UTF-8由于里面有额外的标志信息,所有一个字节只能表示2的7次方128个字符,两个字节只能表示2的11次方2048个字符.而三个字节能表示2的16次方,65536个字符. 由于"汉"的编码27721大于2048了所有两个字节还不够,只能用三个字节来表示. 所有要用1110xxxx 10xxxxxx 10xxxxxx这种格式.把27721对应的二进制从左到右填充XXX符号(实际上不一定从左到右,也可以从右到左,这是涉及到另外一个问题.等会说. 刚说到填充方式可以不一样,于是就出现了Big-Endian,Little-Endian的术语.Big-Endian就是从左到右,Little-Endian是从右到左. 由上面我们可以看出UTF-8在局部的字节错误(丢失、增加、改变)不会导致连锁性的错误,因为 UTF-8 的字符边界很容易检测出来,所以容错性较高。 Unicode版本2 前面说的都是unicode的第一个版本.但65536显然不算太多的数字,用它来表示常用的字符是没一点问题.足够了,但如果加上很多特殊的就也不够了.于是从1996年开始又来了第二个版本.用四个字节表示所有字符.这样就出现了UTF-8,UTF16,UTF-32.原理和之前肯定是完全一样的,UTF-32就是把所有的字符都用32bit也就是4个字节来表示.然后UTF-8,UTF-16就视情况而定了.UTF-8可以选择1至8个字节中的任一个来表示.而UTF-16只能是选两字节或四字节..由于unicode版本2的原理完全是一样的,就不多说了. 前面说了要知道具体是哪种编码方式,需要判断文本开头的标志,下面是所有编码对应的开头标志 EF BB BF UTF-8FE FF UTF-16/UCS-2, big endianFF FE UTF-16/UCS-2, little endianFF FE 00 00 UTF-32/UCS-4, little endian.00 00 FE FF UTF-32/UCS-4, big-endian. 其中的UCS就是前面说的ISO制定的标准,和Unicode是完全一样的,只不过名字不一样.ucs-2对应utf-16,ucs-4对应UTF-32.UTF-8是没有对应的UCS UTF-16 并不是一个完美的选择,它存在几个方面的问题: UTF-16 能表示的字符数有 6 万多,看起来很多,但是实际上目前 Unicode 5.0 收录的字符已经达到 99024 个字符,早已超过 UTF-16 的存储范围;这直接导致 UTF-16 地位颇为尴尬——如果谁还在想着只要使用 UTF-16 就可以高枕无忧的话,恐怕要失望了 UTF-16 存在大小端字节序问题,这个问题在进行信息交换时特别突出——如果字节序未协商好,将导致乱码;如果协商好,但是双方一个采用大端一个采用小端,则必然有一方要进行大小端转换,性能损失不可避免(大小端问题其实不像看起来那么简单,有时会涉及硬件、操作系统、上层软件多个层次,可能会进行多次转换) 另外,容错性低有时候也是一大问题——局部的字节错误,特别是丢失或增加可能导致所有后续字符全部错乱,错乱后要想恢复,可能很简单,也可能会非常困难。(这一点在日常生活里大家感觉似乎无关紧要,但是在很多特殊环境下却是巨大的缺陷) 目前支撑我们继续使用 UTF-16 的理由主要是考虑到它是双字节的,在计算字符串长度、执行索引操作时速度很快。当然这些优点 UTF-32 都具有,但很多人毕竟还是觉得 UTF-32 太占空间了。反过来 UTF-8 也不完美,也存在一些问题: 文化上的不平衡——对于欧美地区一些以英语为母语的国家 UTF-8 简直是太棒了,因为它和 ASCII 一样,一个字符只占一个字节,没有任何额外的存储负担;但是对于中日韩等国家来说,UTF-8 实在是太冗余,一个字符竟然要占用 3多个字节,存储和传输的效率不但没有提升,反而下降了。所以欧美人民常常毫不犹豫的采用 UTF-8,而我们却老是要犹豫一会儿 变长字节表示带来的效率问题——大家对 UTF-8 疑虑重重的一个问题就是在于其因为是变长字节表示,因此无论是计算字符数,还是执行索引操作效率都不高。为了解决这个问题,常常会考虑把 UTF-8 先转换为 UTF-16 或者 UTF-32 后再操作,操作完毕后再转换回去。而这显然是一种性能负担。 当然,UTF-8 的优点也不能忘了: 字符空间足够大,未来 Unicode 新标准收录更多字符,UTF-8 也能妥妥的兼容,因此不会再出现 UTF-16 那样的尴尬 不存在大小端字节序问题,信息交换时非常便捷 容错性高,局部的字节错误(丢失、增加、改变)不会导致连锁性的错误,因为 UTF-8 的字符边界很容易检测出来,这是一个巨大的优点(正是为了实现这一点,咱们中日韩人民不得不忍受 3 字节 1 个字符的苦日子) 那么到底该如何选择呢?因为无论是 UTF-8 和 UTF-16/32 都各有优缺点,因此选择的时候应当立足于实际的应用场景。例如在我的习惯中,存储在磁盘上或进行网络交换时都会采用 UTF-8,而在程序内部进行处理时则转换为 UTF-16/32。对于大多数简单的程序来说,这样做既可以保证信息交换时容易实现相互兼容,同时在内部处理时会比较简单,性能也还算不错。(基本上只要你的程序不是 I/O 密集型的都可以这么干,当然这只是我粗浅的认识范围内的经验,很可能会被无情的反驳)稍微再展开那么一点点……在一些特殊的领域,字符编码的选择会成为一个很关键的问题。特别是一些高性能网络处理程序里更是如此。这时采用一些特殊的设计技巧,可以缓解性能和字符集选择之间的矛盾。例如对于内容检测/过滤系统,需要面对任何可能的字符编码,这时如果还采用把各种不同的编码都转换为同一种编码后再处理的方案,那么性能下降将会很显著。而如果采用多字符编码支持的有限状态机方案,则既能够无需转换编码,同时又能够以极高的性能进行处理。当然如何从规则列表生成有限状态机,如何使得有限状态机支持多编码,以及这将带来哪些限制,已经又成了另外的问题了。 程序员必备:彻底弄懂常见的7种中文字符编码程序开发常见的ASCII、GB2312、GBK、GB18030、UTF8、ANSI、Latin1中文编码到底有何不同?如果你在业务中也曾经被乱码搞晕过,不妨一起探究一下。 一、字符编码要做什么事情?在计算机眼里读到的所有文字都是由0和1组成的字符串,为了能让汉字正常显示在屏幕上,我们需要做以下两件事情: 1、给所有的汉字一个独一无二的数字编号,做一个数字编号到汉字的mapping关系(即字符集)2、把这个数字编号能用0和1表示出来这里需要说明的是,第2件事情并不是直接把数字编号用二进制表示出来那么简单,还要处理多个字连在一起的时候如何做分隔的问题。 例如如果我把”腾”编为1号(二进制00000001,占1byte),把“讯”编为5号(二进制00000101,占1byte),汉字这么多,一定还有一个汉字被编为了133号(二进制00000001 00000101,占2bytes)。 那么现在问题来了,当计算机读到00000001 00000101这一串的时候,它应该显示“腾讯”两个字还是显示那一个133号的文字?因此如何做分隔也是字符编码需要考虑的事情。 第2件事情通常解决方案要么就是规定好每个字长度(例如所有文字都是2bytes,不够的前面用0补齐),要么就是在用0和1表示的时候,不仅需要表示出数字编码,还要暗示给计算机接下来多少个连续byte构成一个字,这个后面UTF8编码中会提到。 我们通常所说的Unicode,其实只做了第1件事情,并且是给全世界所有语言的所有文字或字母一个独一无二的数字编码,这样只要设计一种机制做第2件事情来表示Unicode,就可以显示全球范围内任何文字了。Unicode具体对所有语言的每个字母、文字的数字编号可以从其官方网站Unicode编码表 查询。该官网一大亮点是,中文编码表的体量远远超过其他任何语言…… (为了让文章易懂,我暂时舍弃一些晦涩概念。晦涩地讲,现代字符编码模型其实分5个层次,可以参考链接了解:Unicode Technical Report #17 ,不在我们讨论范围内了) 二、几种常见中文编码的关系如何?几种常见中文编码之间存在兼容性,一图胜千言
所谓兼容性可以简单理解为子集,同时存在也不冲突,不会出现上文所说的不知道是“腾讯”还是133号文字的情况。 图中我们可以看出,ASCII被所有编码兼容,而最常见的UTF8与GBK之间除了ASCII部分之外没有交集,这也是平时业务中最常见的导致乱码场景,使用UTF8去读取GBK编码的文字,可能会看到各种乱码。而GB系列的几种编码,GB18030兼容GBK,GBK又兼容GB2312,下文细讲。 三、ASCII编码ASCII编码每个字母或符号占1byte(8bits),并且8bits的最高位是0,因此ASCII能编码的字母和符号只有128个。有一些编码把8bits最高位为1的后128个值也编码上,使得1byte可以表示256个值,但是这属于扩展的ASCII,并非标准ASCII。通常所说的标准ASCII只有前128个值! ASCII编码几乎被世界上所有编码所兼容(UTF16和UTF32是个例外),因此如果一个文本文档里面的内容全都由ASCII里面的字母或符号构成,那么不管你如何展示该文档的内容,都不可能出现乱码的情况。
GB全称GuoBiao国标,GBK全称GuoBiaoKuozhan国标扩展。GB18030编码兼容GBK,GBK兼容GB2312,其实这三种编码有着非常深厚的渊源,我们放在一起进行比较。 【GB2312】 最早一版的中文编码,每个字占据2bytes。由于要和ASCII兼容,那这2bytes最高位不可以为0了(否则和ASCII会有冲突)。在GB2312中收录了6763个汉字以及682个特殊符号,已经囊括了生活中最常用的所有汉字。(GB2312编码全表:链接) GB2312编码表有个值得注意的点,这个表中也有一些数字和字母,与ASCII里面的字母非常像。例如A3B2对应的是数字2(如下图),但是ASCII里面50(十进制)对应的也是数字2。他们的区别就是输入法中所说的“半角”和“全角”。全角的数字2占两个字节。 通常,我们在打字或编程中都使用半角,即ASCII来编写数字或英文字母。特别是编程中,如果写全角的数字或字母,编译器很有可能不认识……
【GBK】 由于GB2312只有6763个汉字,我汉语博大精深,只有6763个字怎么够?于是GBK中在保证不和GB2312、ASCII冲突(即兼容GB2312和ASCII)的前提下,也用每个字占据2bytes的方式又编码了许多汉字。经过GBK编码后,可以表示的汉字达到了20902个,另有984个汉语标点符号、部首等。值得注意的是这20902个汉字还包含了繁体字,但是该繁体字与台湾Big5编码不兼容,因为同一个繁体字很可能在GBK和Big5中数字编码是不一样的。(GBK编码全表:链接) 【GB18030】 然而,GBK的两万多字也已经无法满足我们的需求了,还有更多可能你自己从来没见过的汉字需要编码。 这时候显然只用2bytes表示一个字已经不够用了(2bytes最多只有65536种组合,然而为了和ASCII兼容,最高位不能为0就已经直接淘汰了一半的组合,只剩下3万多种组合无法满足全部汉字要求)。因此GB18030多出来的汉字使用4bytes编码。当然,为了兼容GBK,这个四字节的前两位显然不能与GBK冲突(实操中发现后两位也并没有和GBK冲突)。 我国在2000年和2005年分别颁布的两次GB18030编码,其中2005年的是在2000年基础上进一步补充。至此,GB18030编码的中文文件已经有七万多个汉字了,甚至包含了少数民族文字。有兴趣的可以到国家标准委官网了解详情,链接 GB2312,GBK,GB18030都是采取了固定长度的办法来解决字符分隔(即前文所提的第2件事情)问题。GBK和GB2312比ASCII多出来的字都是2bytes,GB18030比GBK多出来的字都是4bytes。至于他们具体是如何做到兼容的,可以参考下图:
这图中展示了前文所述的几种编码在编码完成后,前2个byte的值域(用16进制表示)。每个byte可以表示00到FF(即0至255)。ASCII编码由于是单字节,所以没有第2位。因为GBK兼容GB2312,所以理论上上图中GB2312的领土面积也可以算在GBK的范围内,GB18030也同理。 上图只是展示出了比之前编码“多”出来的面积。GB18030由于是4bytes编码,上图只是展示了前2bytes的值域,虽然面积最小,但是如果后2bytes也算上,GB18030新编码的字数实际上远远多于GBK。 可以看出为了做到兼容性,以上所有编码的前2bytes做到了相互值域不冲突,这样就可以允许几种不同编码中的文字同时出现在同一个文本文件中。只要全都按照GB18030编码的规则去解析并展示文件,就不会有乱码出现。实际业务中GB18030很少提到,通常GBK见得比较多,这是因为如果你去看一下GB18030里面所编码的文字,你会发现自己一个字也不认识……
99%的前端写网页时都会加上,99%的后端工程师新建数据库表时都会加上DEFAULT CHARSET=utf8(剩下的1%应该是忘了写)。 之所以我们想让UTF8一统天下,就是因为UTF8可以表示出世界上所有的文字!UTF8与前面说的GB系列编码不兼容,所以如果一个文件中即有UTF8编码的文字,又有GB18030编码的文字,那绝对会有乱码。 Unicode赋予了全世界所有文字和符号一个独一无二的数字编号,UTF8所做的事情就是把这个数字编号表示出来(即解决前文提到的第2件事情)。UTF8解决字符间分隔的方式是数二进制中最高位连续1的个数来决定这个字是几字节编码。0开头的属于单字节,和ASCII码重合,做到了兼容。
以三字节为例,开头第一个字节的”1110”,有连续三个1,说明包括本字节在内,接下来三个字节一起构成了一个文字。凡是不属于文字首字节的byte都以“10”开头,上表中标注X的位置才是真正用来表示Unicode数值的。 这种巧妙设计,把Unicode的数值和每个字的字节数融合在一起,最坏情况是6个字节表示一个字,已经足够表示世界上所有语言的所有文字了。不过从这种表示方式也可以很显然地看出来,UTF8和GBK没有任何关系,除了都兼容ASCII以外。
举例说明,中文“鹅”字,Unicode十进制值为40517(16进制为9E45,2进制为1001 1110 0100 0101)。这个2进制值长度为12位,查询上面表格发现,二字节不够表示,四字节太长,三字节刚好,因此可以表示为 11101001 10111001 10000101,换算为16进制即E9B985,这就是“鹅”字的UTF8编码,占3字节。另外,经查询,“鹅”的GBK编码为B6EC,和UTF8的值完全不相干。 对于中文汉字来说,所有常用汉字的Unicode值都可以用3字节的UTF8表示出来,而GBK编码的汉字基本是2字节(GB18030虽4字节但是日常没人会写那些字)。这也就导致了,如果把GBK编码的中文文本另存为UTF8编码,体积会大50%左右。这也是UTF8的一点小瑕疵,存储同样的汉字,体积比GBK要大50%。 不过在“可表示世界上所有文字”这一巨大优势面前,UTF8的这点小瑕疵可以忽略了,所以日常开发中最常使用UTF8。 六、其他经常遇到的编码【ANSI编码】 准确说,并不存在哪种具体的编码方式叫做ANSI,它只是一个Windows操作系统上的别称而已。在中文简体Windows操作系统上,ANSI就是GBK;在泰语操作系统上,ANSI就是TIS-620(一种泰语编码);在韩语操作系统上,ANSI就是EUC-KR(一种韩语编码)。并且所谓的ANSI只存在于Windows操作系统上。 【Latin1编码(又名ISO-8859-1编码)】 相信99%的人第一次听到Latin1都是在使用Mysql数据库的时候接触到的。Latin1是Mysql数据库表的默认编码方式。Latin1也是单字节编码方式,也就是说最多只能表示256个字母或符号,并且前128个和ASCII完全吻合。 Latin1在ASCII基础上又充分利用了后面那128个值,赋予他们一些泰语、希腊语等字母或符号,将1个字节的256个值全部占满了。因为项目中用不到,我对这种编码的细节没兴趣了解,唯一感兴趣的是为什么Mysql选它做默认编码(为什么默认编码不是UTF8)?以及如果忘了设置Mysql表的编码方式时,用Latin1存储中文会不会出问题?
为什么默认编码是Latin1而不是UTF8?原因之一是Mysql最开始是某瑞典公司搞的项目,故默认collate都是latin1_swedish_ci。swedish可以理解为其私心,不过latin1不管是否出于私心目的,单字节编码作为默认值肯定是比多字节做默认值更不容易在插入数据时报错。 既然Latin1为单字节编码,并且将1个字节的所有256个值全部占满,因此理论上把任何编码的值塞到Latin1字段都是可以存的(无非就是显示乱码而已)。 假设默认为UTF8这一多字节编码,在用户误把一个不使用UTF8编码的字符串存进去时,很有可能因为该字符串不符合UTF8的编码要求导致Mysql根本没法处理。这也是单字节编码的一大好处:显示可以乱码,但是里面的数据值永远正确。 用Latin1存储中文有没有问题?答案是没有问题,但是并不建议。例如你把UTF8编码的“讯”字(UTF8编码为0xE8AEAF,占三个字节)存入了Latin1编码的Mysql表,那么在Mysql眼里,你存入的并不是一个“讯”字,而是三个Latin1的字母(0xE8,0xAE,0xAF)。本质上,你存的数据值依然是0xE8AEAF,这种“欺骗”Mysql的行为并没有导致数据丢失,只不过你需要注意读取出来该值的时候,自己要以UTF8编码的方式显示出来,要不然就是乱码。 因此,用Latin1存任何文字技术上都可以,但是经常会导致数据显示乱码。通常的解决方案,就是让UTF8一统天下,建表的时候就声明charset为utf8。 文章最后,遗留一个问题。既然有这么多编码形式,如果给定一个文本文件,不告诉你是什么编码,如何用程序进行检测?比较有代表性的编码检测库为python的chardet,其具体的原理,且待下回分解~ chardet 工作原理https://chardet.readthedocs.io/en/latest/how-it-works.html 语言/编码检测的复合方法[注意:本文最初在第19届国际Unicode会议(圣何塞)上发表。从那时起,该实现经历了一段时间的实际使用,并且我们在此过程中进行了许多改进。一个主要的变化是,我们现在使用正序列来检测单字节字符集,请参见第4.7和4.7.1节。``本文是在通用字符集检测代码不属于Mozilla主要来源的情况下编写的。(请参阅第8节)。从那以后,代码被检入到树中。有关更多更新的实现,请参见Mozilla源代码树上的开放源代码。-作者。2002-11-25。] 1.总结:本文介绍了三种自动检测方法来确定没有显式字符集声明的文档编码。我们讨论了每种方法的优缺点,并提出了一种组合方法,其中将所有这三种类型的检测方法都用于发挥其最大优势并补充其他检测方法。我们认为,自动检测在帮助浏览器用户从频繁使用字符编码菜单转变为更不希望使用编码菜单的更为理想的状态方面起着重要作用。我们设想向Unicode的过渡。用户必须知道如何正确显示字符-无论是本机编码还是Unicode编码之一。 2.背景:自计算机时代开始以来,已经创建了许多编码方案来表示用于计算机化数据的各种书写脚本/字符。随着全球化的到来和互联网的发展,跨越语言和地区边界的信息交流变得越来越重要。但是,多种编码方案的存在构成了很大的障碍.Unicode编码提供了一种通用编码方案,但是由于种种原因,它到目前为止尚未取代现有的区域编码方案。尽管事实上许多W3C和IETF建议都将UTF-8用作默认编码,例如XML,XHTML,RDF等。因此,当今的全球软件应用程序除支持Unicode外还需要处理多种编码。 当前的工作是在开发Internet浏览器的背景下进行的。为了当今在网络上使用不同的编码来处理多种语言,已经付出了很多努力。为了获得正确的显示结果,浏览器应该能够通过字符编码菜单利用http服务器,网页或最终用户提供的编码信息。不幸的是,许多http服务器和网页都缺少这种类型的信息。此外,大多数普通用户无法通过手动操作字符编码菜单来提供此信息。没有此字符集信息,网页有时会显示为``垃圾''字符,并且用户无法访问所需的信息。这也使用户得出结论,认为他们的浏览器运行不正常或有故障。 随着越来越多的Internet标准协议将Unicode指定为默认编码,毫无疑问,将向网页上使用Unicode的重大转变。良好的通用自动检测功能如果可以无缝运行而无需用户使用编码菜单,则可以为这种转变做出重要贡献。在这种情况下,逐渐转换为Unicode可能会很轻松,并且不会对Web用户造成明显影响,因为对于用户而言,页面只是简单地正确显示而无需他们执行任何操作或不注意编码菜单.``通过使编码问题对用户而言越来越不明显,可以帮助实现这种平稳过渡。在这种情况下,自动检测将发挥重要作用。 3.问题范围:3.1。通用架构 让我们从一个通用模式开始。对于大多数应用程序,以下内容代表自动检测使用的一般框架: 输入数据->``自动检测器->返回结果'' 应用程序/程序从自动检测器获取返回的结果,然后将此信息用于有多种用途,例如设置数据的编码,按原始创建者的意图显示数据,将其传递给其他程序等等。 本文讨论的自动检测方法以Internet浏览器应用程序为例。但是,这些自动检测方法可以轻松适用于其他类型的应用程序。 3.2. 浏览器和自动检测浏览器可能会使用某些检测算法来自动检测网页的编码。程序可以采用不同的编码方式以多种方式解释一段文本,但是在某些极少数情况下,页面作者只需要一种解释即可。通常,这是用户唯一合理的方式以预期的语言正确看到该页面。 为了列出设计自动检测算法的主要因素,我们从有关输入文本及其处理方法的某些假设开始。以网页数据为例, 1.输入文本由特定读者可读的单词/句子组成。语言。(=数据不乱码。) 2.输入的文本来自Internet上的典型网页。(=数据通常不是来自某些死语或古老的语言。) 3.输入文本可能包含与编码无关的外来噪音,例如HTML标签,非本地单词(例如中文文档中的英语单词),空格和其他格式/控制字符。 覆盖所有已知的语言和编码以进行自动检测几乎是不可能完成的任务。在当前的方法中,我们试图涵盖东亚语言中使用的所有流行编码,并提供了一个通用模型来同时处理单字节编码。选择了俄语编码作为后一种类型的实现示例,并且选择了我们的单字节编码测试平台。 4.目标多字节编码包括UTF8,Shift-JIS,EUC-JP,GB2312,Big5,EUC-TW,EUC-KR,ISO2022-XX和HZ。 5.提供一个处理单字节编码的通用模型。俄罗斯语言编码(KOI8-R,ISO8859-5,window1251,Mac-cyrillic,ibm866,ibm855)在测试台中作为实现示例进行了介绍。 4.三种自动检测方法:4.1。介绍: 在本节中,我们讨论3种不同的方法来检测文本数据的编码。它们是1)编码方案方法,2)字符分布和3)2字符序列分布。每个人都有其优点和缺点,但是,如果我们以互补的方式使用所有三个,则结果可能会非常令人满意。 4.2。编码方案方法:对于多字节编码,此方法可能是最明显的方法,也是最常尝试的方法。在任何多字节编码编码方案中,并未使用所有可能的代码点。如果在验证某种编码时遇到非法字节或字节序列(即未使用的代码点),我们可以立即得出结论,这不是正确的猜测。少数代码点还特定于某种编码,该事实可能会导致立即得出肯定的结论。Netscape Communications的Frank Tang开发了一种非常有效的算法,可以通过并行状态机使用编码方案来检测字符集。他的基本思想是: 对于每种编码方案,实现一个状态机以验证此特定编码的字节序列。检测器收到的每个字节,都会将该字节提供给每个可用的活动状态机,一次提供一个字节。状态机根据其先前的状态及其接收的字节来更改其状态。状态机中有3个自动检测器感兴趣的状态: 起始状态:这是开始的状态,或者已识别出字符的合法字节序列(即有效代码点)。 ME状态:这表明状态机识别出了特定于其设计的字符集的字节序列,并且没有其他可能的编码可以包含此字节序列。这将导致检测器立即得到肯定的答复。 ERROR状态:这表明状态机为该编码识别了非法字节序列。这将立即导致对该编码的否定答案。从此以后,检测器将从考虑中排除此编码。在典型示例中,一个状态机最终将提供肯定的答案,而其他所有状态机将提供否定的答案。 当前工作中使用的PSM(并行状态机)版本是Frank Tang原始工作的修改。每当状态机达到START状态(表示它已成功识别合法字符)时,我们都会查询状态机以查看此字符有多少字节。该信息有两种使用方式。 首先,对于UTF-8编码,如果标识了几个多字节字符,则输入数据几乎不可能是UTF-8以外的任何其他数据。因此,我们计算了UTF-8状态机标识的多字节字符的数量。当达到一定数量(=阈值)时,得出结论。 其次,对于其他多字节编码,此信息将馈送到字符分布分析器(请参见下文),以便分析器可以处理字符数据,而不是原始数据。4.3。字符分配方法: 在任何给定的语言中,某些字符比其他字符更常用。此事实可用于为每种语言脚本设计数据模型。这对于具有大量字符的语言(例如中文,日语和韩语)特别有用。我们经常听到有关这种分布统计的轶事,但是我们没有发现很多公开的结果。因此,在以下讨论中,我们主要依靠自己收集的数据。 4.3.1。简体中文:
我们对GB2312中编码的6763个汉字数据进行了研究,得出以下分布结果: 最常见字符数 累计百分比 10 0.11723 64 0.31983 128 0.45298 256 0.61872 512 0.79135 1024 0.92260 2048 0.98505 4096 0.99929 6763 1.00000
表1.简体中文字符分配表 4.3.2。繁体中文: 台湾普通话促进委员会每年进行的研究表明,使用Big5编码的繁体中文具有类似的结果。 最常见字符数 累计百分比 100.11713 640.29612 1280.42261 2560.57851 5120.74851 10240.89384 20480.97583 40960.99910
表2.繁体字分布表 4.3.3。日本: 我们收集了自己的日语数据,然后编写了实用程序对其进行分析。 最常见字符数 累计百分比 10 0.27098 64 0.66722 128 0.77094 256 0.85710 512 0.92635 1024 0.97130 2048 0.99431 4096 0.99981 1.00000
表3. 日语字符分布表 4.3.4. 韩语:同样,对于韩语用户,我们从Internet收集了自己的数据并在其上运行实用程序。结果如下: 最常见字符数 累计百分比 10 0.25620 64 0.64293 128 0.79290 256 0.92329 512 0.98653 1024 0.99944 2048 0.99999 4096 0.99999
表4 ..韩文字符分布表
4.4。分配结果的一般特征: 在所有这四种语言中,我们发现很少的编码点集覆盖了我们定义的应用范围中使用的很大比例的字符。此外,仔细检查那些常用的编码点会发现它们分散在相当宽的编码范围内这为我们提供了一种克服编码方案分析器中遇到的常见问题的方法,即不同的国家编码可能共享重叠的代码点。由于这些语言最频繁出现的集合具有上述特征,因此之间存在重叠问题在编码方案方法中,不同的编码在分发方法中将无关紧要。 4.5。分析算法:为了基于字符频率/分布统计信息识别语言的特征,我们需要一种算法来从文本输入流中计算值。此值应显示此文本流采用某种字符编码的可能性。一个自然的选择可能是根据每个字符的频率权重来计算该值。但是从我们使用各种字符编码进行的实验中,我们发现这种方法不是必需的,它使用了过多的内存和CPU能力。简化版本提供了非常令人满意的结果,并且使用更少的资源并且运行更快。 在当前方法中,给定编码中的所有字符都分为两类,``经常使用''和``不经常使用''。如果一个字符在频率分布表的前512个字符中,则归为经常使用的字符。选择数字512是因为它覆盖了4种语言输入文本中任何一个的大量累积百分比,而只占用了一小部分编码点。我们计算一批输入文本中任一类别中的字符数,然后计算一个浮点值,我们称为“分配比率”。 分配比率定义如下: 分配比率= 512个最常用字符的出现次数除以其余字符的出现次数。 实际上,所测试的每种多字节编码都显示出不同的分配比率。然后,可以从该比率计算给定编码的原始输入文本的置信度。下面对每种编码的讨论应该使这一点更加清楚。 4.6。分配比率和置信度:让我们看一下4种语言数据以了解分配比率的差异。首先请注意,我们以两种方式使用术语分配比率。为语言脚本/字符集而不是编码定义了一个``理想的分配比率''。如果语言脚本/字符集由不止一种编码表示,则对于每种编码,我们将计算``实际的分配比率''通过将字符分类为``常用''或``不常用''类别来输入数据。然后将该值与语言脚本/字符集的理想分配比率进行比较。基于获得的实际分配比率,我们可以如下所述为每组输入数据计算置信度。 4.6.1。简体中文(GB2312):GB2312编码包含两个级别的汉字。级别1包含3755个字符,级别2包含3008个字符。级别1的字符比级别2的字符更频繁使用,并且不足为奇的是,GB 2312的最常用字符列表上的所有512个字符均在级别1内。字符均匀地分散在3755个代码点中。在第1级中,这些字符占所有编码点的13.64%,但在典型的中文文本中,这些字符占79.135%。在理想情况下,一段包含足够字符的中文文本应该返回以下内容: ``分配比率= 0.79135 /(1-0.79135)= 3.79 对于使用相同编码方案的随机生成的文本,如果不使用2级字符,则比率应约为512 /(3755-512)= 0.157。 如果考虑到第2级字符,我们可以假设每个第1级字符的平均概率为p1,而第2级字符的平均概率为p2。然后计算为: 512 * p1 /(3755 * p1 + 3008 * p2 512 * p1)= 512 /(3755 + 3008 * p2 / p1-512) 显然,该值甚至更小。在以后的分析中,我们仅使用最坏的情况进行比较。 4.6.2。大5:Big5和EUC-TW(即CNS字符集)编码的故事非常相似.Big5还以2级编码中文字符。最常用的512个字符均匀地分散在5401 1级字符中。我们从big5编码的文本中可以获得的理想比率是: 分配比率= 0.74851 /(1-0.74851)= 2.98 并且对于随机生成的文本,其比率应接近 512 /(5401-512)= 0.105, 因为Big5级别1字符几乎与CNS平面1字符相同,相同的分析适用于EUC-TW。 4.6.3。日语Shift_JIS和EUC-JP:对于日语,平假名和片假名通常比汉字使用更多。由于Shift-JIS和EUC-JP在不同的编码范围内对平假名和片假名进行编码,因此我们仍然可以使用此方法来区分这两种编码。那些最经常使用的512个汉字字符也均匀地分散在2965 JIS Level 1汉字集之间。相同的分析得出以下分配比率: 分配比率= 0.92635 /(1-0.92635)= 12.58 对于随机生成日语文本数据,比率至少应为 512 /(2965 + 63 + 83 + 86-512)= 0.191。 计算包括片假名(63),平假名(83)和片假名(86)。 4.6.4。韩国EUC-KR:在EUC-KR编码中,典型韩文文本中实际使用的Hanja(中文)字符的数量微不足道。以这种编码方式编码的2350个韩文字符按其发音排列。在频率表中,我们通过分析大量的韩文文本数据获得了最常用的字符均匀分布在这2350个代码点中的信息。使用相同的分析,在理想情况下,我们得到: 分配比率= 0.98653 /(1-0.98653)= 73.24 对于随机生成的韩文,应为: 512 /(2350-512)= 0.279。 4.6.5。计算置信度:通过前面对每种语言脚本的讨论,我们可以为每个数据集定义置信度级别,如下所示: 置信度检测(InputText){``InputText中的每个多字节字符。{ TotalCharacterCount++;如果该字符在512个最频繁的字符中,则FrequentCharacterCount ++;} 比率= FrequentCharacterCount/(TotalCharacterCount-FreqentCharacterCount);置信度=比率/ CHARSET_RATIO;回报信心;} 给定集合数据的置信度定义为输入数据的分配比率除以通过前面各节中的分析获得的理想分配比率。 4.7. 两字符序列分配方法:在仅使用少量字符的语言中,我们需要进一步计算每个单个字符的出现次数。字符组合揭示了更多的语言特性信息。我们将2字符序列定义为2个字符,它们在输入文本中紧挨着出现,在这种情况下顺序很重要。正如并非所有字符在一种语言中使用频率一样高一样,2-字符序列分布也被证明与语言/编码密切相关。此特征可用于语言检测。这样可以提高检测字符编码的信心,并且在检测单字节语言时非常有用。 让我们以俄语为例。我们下载了大约20MB的俄语纯文本,并编写了一个分析文本的程序。该程序共发现21,199,528个2字符序列。在我们发现的序列中,其中一些与我们的考虑无关,例如空间-空间组合。这些序列被视为噪声,并且它们的出现不包括在分析中。在我们用来检测俄语编码的数据中,剩下的20,134,122个2字符序列出现了。这覆盖了数据中发现的所有序列出现的约95%。构建我们的语言模型所使用的序列可以是分为4096个不同的序列,在我们的20,134,122个样本中,其中1961年出现的次数少于3次。我们将这1961个序列称为该语言的负序列集。 4.7.1。确定置信度的算法对于单字节语言,我们将置信度级别定义如下: 置信度检测(InputText){为InputText中的每个字符。{。如果字符不是符号或标点符号TotalCharacters ++;在频率表中找到其频率顺序;If(频率顺序 |


 [ 几种中文编码的兼容性 ]
[ 几种中文编码的兼容性 ]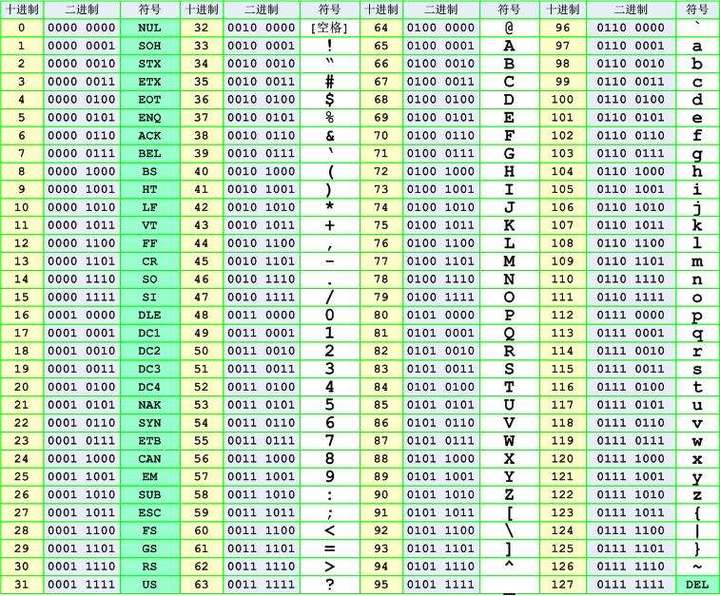 [ ASCII编码表 ]
[ ASCII编码表 ]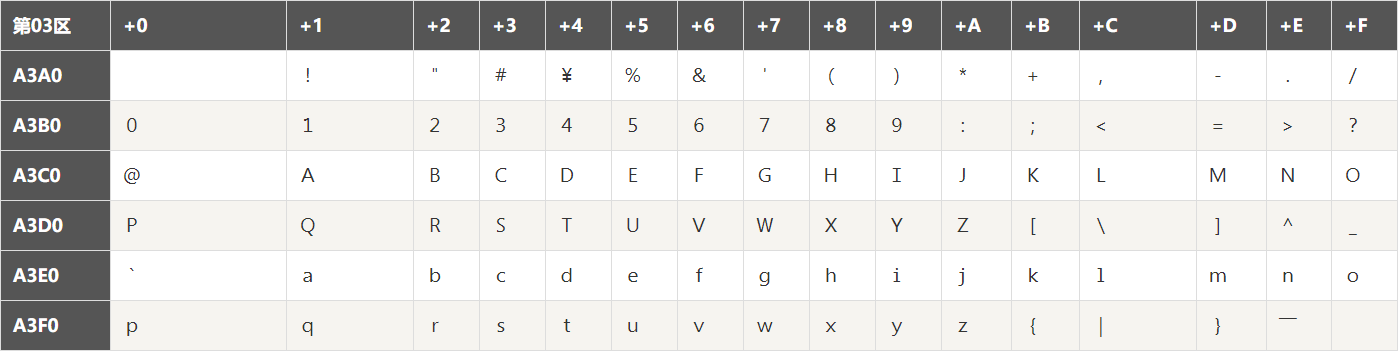 [ GB2312与ASCII重合的部分字符 ]
[ GB2312与ASCII重合的部分字符 ]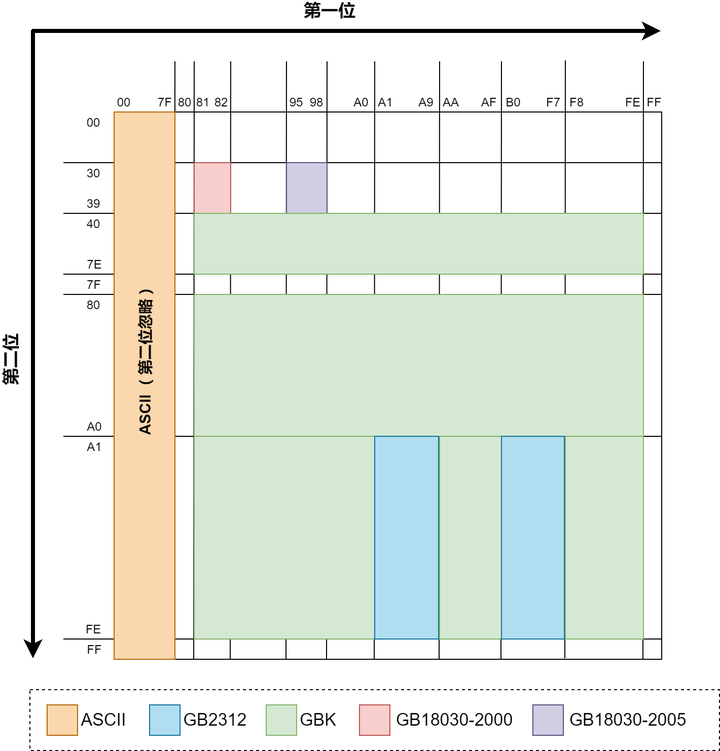 [ 几种不同编码的前2字节值域 ]
[ 几种不同编码的前2字节值域 ]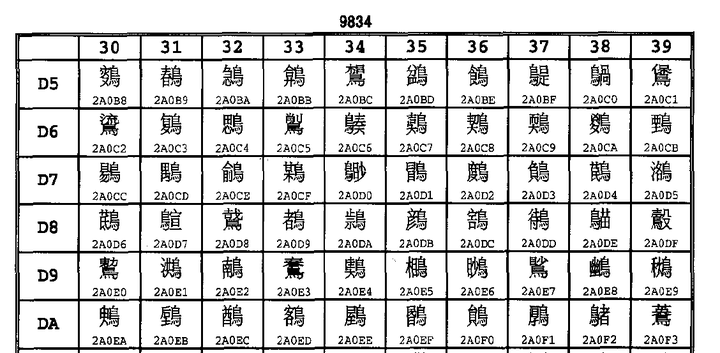 [ GB18030编码的部分汉字 ]
[ GB18030编码的部分汉字 ]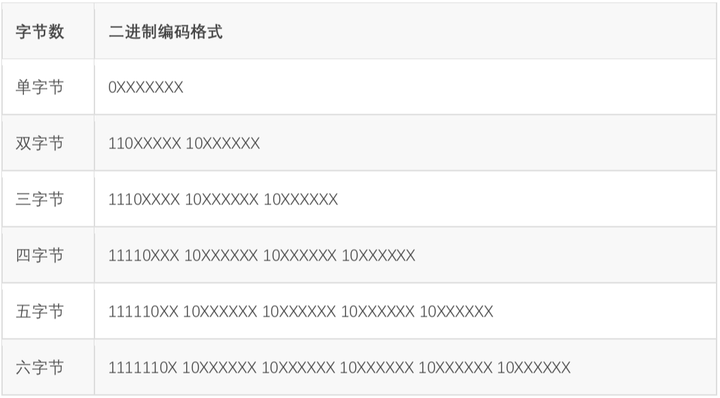
 [ ;amp;amp;amp;amp;quot;鹅;amp;amp;amp;amp;quot;字的UTF8编码计算过程 ]
[ ;amp;amp;amp;amp;quot;鹅;amp;amp;amp;amp;quot;字的UTF8编码计算过程 ]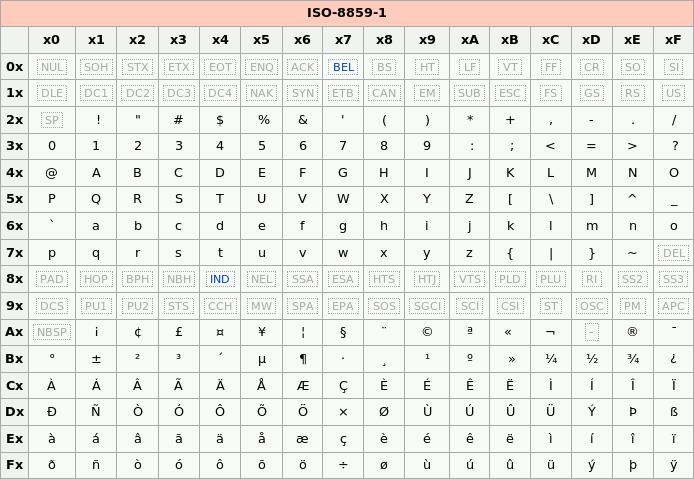 [ Latin1编码表 ]
[ Latin1编码表 ]【本文地址】